mirror of
https://github.com/huggingface/candle.git
synced 2025-06-15 10:26:33 +00:00
Module Docs (#2624)
* update whisper * update llama2c * update t5 * update phi and t5 * add a blip model * qlamma doc * add two new docs * add docs and emoji * additional models * openclip * pixtral * edits on the model docs * update yu * update a fe wmore models * add persimmon * add model-level doc * names * update module doc * links in heira * remove empty URL * update more hyperlinks * updated hyperlinks * more links * Update mod.rs --------- Co-authored-by: Laurent Mazare <laurent.mazare@gmail.com>
This commit is contained in:
@ -1,8 +1,11 @@
|
||||
//! Based on the BLIP paper from Salesforce Research.
|
||||
//!
|
||||
//! See "BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//! - [Arxiv](https://arxiv.org/abs/2201.12086)
|
||||
//! - [Github](https://github.com/salesforce/BLIP)
|
||||
//! The blip-image-captioning model can generate captions for an input image.
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//!
|
||||
|
||||
use super::blip_text;
|
||||
|
||||
@ -1,9 +1,12 @@
|
||||
//! Implementation of BLIP text encoder/decoder.
|
||||
//!
|
||||
//! See "BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//! https://arxiv.org/abs/2201.12086
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//!
|
||||
|
||||
use super::with_tracing::{linear, Embedding, Linear};
|
||||
use candle::{Module, Result, Tensor, D};
|
||||
use candle_nn::{layer_norm, LayerNorm, VarBuilder};
|
||||
|
||||
@ -1,10 +1,8 @@
|
||||
//! Implementation of the ChatGLM2/3 models from THUDM.
|
||||
//!
|
||||
//! See:
|
||||
//! - ChatGLM3: ["ChatGLM3: Advancing Multilingual Conversational Language Models with High-Quality Data"](https://github.com/THUDM/ChatGLM3)
|
||||
//! - ChatGLM2: ["ChatGLM2: An Open Bilingual Chat LLM"](https://github.com/THUDM/ChatGLM2-6B)
|
||||
//! - 💻 [Github](https://github.com/THUDM/ChatGLM3) ChatGLM3: Advancing Multilingual Conversational Language Models with High-Quality Data
|
||||
//! - 💻 [Github](https://github.com/THUDM/ChatGLM2-6B) ChatGLM2-6B.
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear_b as linear, Linear};
|
||||
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
|
||||
use candle_nn::VarBuilder;
|
||||
|
||||
@ -3,10 +3,9 @@
|
||||
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! - [GH Link](https://github.com/OFA-Sys/Chinese-CLIP)
|
||||
//! - Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py)
|
||||
//! - 💻 [GH Link](https://github.com/OFA-Sys/Chinese-CLIP)
|
||||
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py)
|
||||
//!
|
||||
|
||||
use candle::{Module, Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
|
||||
|
||||
@ -3,8 +3,8 @@
|
||||
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! https://github.com/OFA-Sys/Chinese-CLIP
|
||||
//! https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py
|
||||
//! - 💻 [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)
|
||||
//! - 💻 [HF](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py)
|
||||
|
||||
use candle::{DType, Device, IndexOp, Module, Result, Tensor};
|
||||
use candle_nn as nn;
|
||||
@ -67,7 +67,7 @@ impl Default for ChineseClipTextConfig {
|
||||
}
|
||||
|
||||
impl ChineseClipTextConfig {
|
||||
/// referer: https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json
|
||||
/// [referer](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json)
|
||||
pub fn clip_vit_base_patch16() -> Self {
|
||||
Self {
|
||||
vocab_size: 21128,
|
||||
|
||||
@ -3,8 +3,8 @@
|
||||
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! https://github.com/OFA-Sys/Chinese-CLIP
|
||||
//! https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py
|
||||
//! - 💻 [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)
|
||||
//! - 💻 [GH](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py_
|
||||
|
||||
use candle::{DType, IndexOp, Module, Result, Shape, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
@ -49,7 +49,7 @@ impl Default for ChineseClipVisionConfig {
|
||||
}
|
||||
|
||||
impl ChineseClipVisionConfig {
|
||||
/// referer: https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json
|
||||
/// [referer](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json)
|
||||
pub fn clip_vit_base_patch16() -> Self {
|
||||
Self {
|
||||
hidden_size: 768,
|
||||
|
||||
@ -3,8 +3,10 @@
|
||||
//! Contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! - [GH Link](https://github.com/openai/CLIP)
|
||||
//! - Transformers Python [reference implementation](https://github.com/huggingface/transformers/tree/f6fa0f0bf0796ac66f201f23bdb8585de1609add/src/transformers/models/clip)
|
||||
//! - 💻 [GH Link](https://github.com/openai/CLIP)
|
||||
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/tree/f6fa0f0bf0796ac66f201f23bdb8585de1609add/src/transformers/models/clip)
|
||||
//! - 🤗 [HF Model](https://huggingface.co/openai/clip-vit-large-patch14-336)
|
||||
//!
|
||||
|
||||
use self::{
|
||||
text_model::{Activation, ClipTextTransformer},
|
||||
|
||||
@ -3,8 +3,8 @@
|
||||
//! Contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! https://github.com/openai/CLIP
|
||||
//! https://github.com/huggingface/transformers/tree/f6fa0f0bf0796ac66f201f23bdb8585de1609add/src/transformers/models/clip
|
||||
//! - [GH](https://github.com/openai/CLIP)
|
||||
//! - [Code](https://github.com/huggingface/transformers/tree/f6fa0f0bf0796ac66f201f23bdb8585de1609add/src/transformers/models/clip)
|
||||
|
||||
use candle::{DType, Device, IndexOp, Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
//! CodeGeeX4 - A multi-language code generation model
|
||||
//!
|
||||
//! See "CodeGeeX: A Pre-Trained Model For Code Generation with Multilingual Evaluations on HumanEval-X", Qian et al. 2023
|
||||
//! - [Arxiv](https://arxiv.org/abs/2303.17568)
|
||||
//! - [Github](https://github.com/THUDM/CodeGeeX)
|
||||
//! A Pre-Trained Model For Code Generation with Multilingual Evaluations on HumanEval-X"
|
||||
//!
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2303.17568)
|
||||
//! - 💻 [Github](https://github.com/THUDM/CodeGeeX)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear_b as linear, Linear};
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
//! ConvMixer implementation.
|
||||
//!
|
||||
//! See "Patches Are All You Need?" by Trockman et al. 2022
|
||||
//! - [Arxiv](https://arxiv.org/abs/2201.09792)
|
||||
//! - [Github](https://github.com/locuslab/convmixer)
|
||||
//!
|
||||
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2201.09792)
|
||||
//! - 💻 [Github](https://github.com/locuslab/convmixer)
|
||||
//!
|
||||
use candle::Result;
|
||||
use candle_nn::{batch_norm, Conv2dConfig, Module, VarBuilder};
|
||||
|
||||
|
||||
@ -1,13 +1,16 @@
|
||||
//! ConvNeXt implementation.
|
||||
//!
|
||||
//! See ["A ConvNet for the 2020s" Liu et al. 2022](https://arxiv.org/abs/2201.03545)
|
||||
//! and
|
||||
//! ["ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders" Woo et al. 2023](https://arxiv.org/abs/2301.00808)
|
||||
//! This candle implementation uses a pre-trained ConvNeXt network for inference. The
|
||||
//! classification head has been trained on the ImageNet dataset and returns the
|
||||
//! probabilities for the top-5 classes.
|
||||
//!
|
||||
//! Original code:
|
||||
//! - [ConvNeXt](https://github.com/facebookresearch/ConvNeXt/)
|
||||
//! - [ConvNeXt-V2](https://github.com/facebookresearch/ConvNeXt-V2/)
|
||||
//! - [timm](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/convnext.py)
|
||||
//! - 💻 [ConvNeXt](https://github.com/facebookresearch/ConvNeXt/)
|
||||
//! - 💻 [ConvNeXt-V2](https://github.com/facebookresearch/ConvNeXt-V2/)
|
||||
//! - 💻 [timm](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/convnext.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.03545) A ConvNet for the 2020s
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2301.00808) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
|
||||
//!
|
||||
|
||||
use candle::shape::ShapeWithOneHole;
|
||||
use candle::{Result, D};
|
||||
|
||||
@ -2,9 +2,9 @@
|
||||
//!
|
||||
//! Flux is a 12B rectified flow transformer capable of generating images from text descriptions.
|
||||
//!
|
||||
//! - [Hugging Face Model](https://huggingface.co/black-forest-labs/FLUX.1-schnell)
|
||||
//! - [GitHub Repository](https://github.com/black-forest-labs/flux)
|
||||
//! - [Blog Post](https://blackforestlabs.ai/announcing-black-forest-labs/)
|
||||
//! - 🤗 [Hugging Face Model](https://huggingface.co/black-forest-labs/FLUX.1-schnell)
|
||||
//! - 💻 [GitHub Repository](https://github.com/black-forest-labs/flux)
|
||||
//! - 📝 [Blog Post](https://blackforestlabs.ai/announcing-black-forest-labs/)
|
||||
//!
|
||||
//! # Usage
|
||||
//!
|
||||
|
||||
@ -1,9 +1,8 @@
|
||||
//! [Hiera] inference implementation based on timm.
|
||||
//! Hiera inference implementation based on timm.
|
||||
//!
|
||||
//! See "[Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles]"
|
||||
//! [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles]: https://arxiv.org/abs/2306.00989
|
||||
//!
|
||||
//! [Hiera]: https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/hiera.py
|
||||
//! - 💻 [Hiera](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/hiera.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2306.00989). Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
|
||||
|
||||
use candle::{Result, D};
|
||||
use candle_nn::{conv2d, layer_norm, linear, ops::softmax, Conv2dConfig, Func, VarBuilder};
|
||||
|
||||
@ -2,7 +2,9 @@
|
||||
//!
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
|
||||
//!
|
||||
//! Based on the [llama2.c](https://github.com/karpathy/llama2.c) implementation
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-llama2)
|
||||
//! - 💻 llama2.c [GH Link](https://github.com/karpathy/llama2.c)
|
||||
//!
|
||||
|
||||
use candle::{DType, Device, IndexOp, Result, Tensor, D};
|
||||
use candle_nn::linear_no_bias as linear;
|
||||
|
||||
@ -1,13 +1,12 @@
|
||||
//! The LLaVA (Large Language and Vision Assistant) model.
|
||||
//!
|
||||
//! This provides the main model implementation combining a vision tower (CLIP) with
|
||||
//! language model (Llama) for multimodal capabilities.
|
||||
//! language model (Llama) for multimodal capabilities. The architecture implements the training-free projection technique.
|
||||
//!
|
||||
//! The architecture implements the training-free projection technique from the paper:
|
||||
//! [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485).
|
||||
//!
|
||||
//! - [GH Link](https://github.com/haotian-liu/LLaVA/tree/main)
|
||||
//! - 💻[GH Link](https://github.com/haotian-liu/LLaVA/tree/main)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2304.08485)/ Visual Instruction Tuning
|
||||
//!
|
||||
|
||||
pub mod config;
|
||||
pub mod utils;
|
||||
|
||||
|
||||
@ -1,9 +1,27 @@
|
||||
//! mimi model
|
||||
//!
|
||||
//! Mimi is a state-of-the-art audio neural codec.
|
||||
//! [Mimi](https://huggingface.co/kyutai/mimi) is a state of the art audio
|
||||
//! compression model using an encoder/decoder architecture with residual vector
|
||||
//! quantization. The candle implementation supports streaming meaning that it's
|
||||
//! possible to encode or decode a stream of audio tokens on the flight to provide
|
||||
//! low latency interaction with an audio model.
|
||||
//!
|
||||
//! - [HuggingFace Model Card](https://huggingface.co/kyutai/mimi)
|
||||
//! - [GitHub](https://github.com/kyutai-labs/moshi)
|
||||
//! - 🤗 [HuggingFace Model Card](https://huggingface.co/kyutai/mimi)
|
||||
//! - 💻 [GitHub](https://github.com/kyutai-labs/moshi)
|
||||
//!
|
||||
//!
|
||||
//! # Example
|
||||
//! ```bash
|
||||
//! # Generating some audio tokens from an audio files.
|
||||
//! wget https://github.com/metavoiceio/metavoice-src/raw/main/assets/bria.mp3
|
||||
//! cargo run --example mimi \
|
||||
//! --features mimi --release -- \
|
||||
//! audio-to-code bria.mp3 bria.safetensors
|
||||
//!
|
||||
//! # And decoding the audio tokens back into a sound file.
|
||||
//! cargo run --example mimi
|
||||
//! --features mimi --release -- \
|
||||
//! code-to-audio bria.safetensors bria.wav
|
||||
//!
|
||||
|
||||
// Copyright (c) Kyutai, all rights reserved.
|
||||
|
||||
@ -3,9 +3,15 @@
|
||||
//! Mix of Multi-scale Dilated and Traditional Convolutions (MMDiT) is an architecture
|
||||
//! introduced for Stable Diffusion 3, with the MMDiT-X variant used in Stable Diffusion 3.5.
|
||||
//!
|
||||
//! - [Research Paper](https://arxiv.org/abs/2403.03206)
|
||||
//! - ComfyUI [reference implementation](https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py)
|
||||
//! - Stability-AI [MMDiT-X implementation](https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py)
|
||||
//! - 📝 [Research Paper](https://arxiv.org/abs/2403.03206)
|
||||
//! - 💻 ComfyUI [reference implementation](https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py)
|
||||
//! - 💻 Stability-AI [MMDiT-X implementation](https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py)
|
||||
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//!
|
||||
|
||||
pub mod blocks;
|
||||
pub mod embedding;
|
||||
|
||||
@ -1,3 +1,19 @@
|
||||
//! Candle implementations for various deep learning models
|
||||
//!
|
||||
//! This crate provides implementations of popular machine learning models and architectures for different modalities.
|
||||
//!
|
||||
//! - Large language models: [`llama`], [`phi3`], [`mamba`], [`mixtral`], [`bert`], ...
|
||||
//! - Text to text models: [`t5`], ...
|
||||
//! - Image to text models: [`blip`], ...
|
||||
//! - Text to image models: [`stable_diffusion`] and [`wuerstchen`], ...
|
||||
//! - Audio models: [`whisper`], [`encodec`], [`metavoice`], [`parler_tts`], ...
|
||||
//! - Computer vision models: [`dinov2`], [`convmixer`], [`efficientnet`], ...
|
||||
//!
|
||||
//! Some of the models also have quantized variants, e.g. [`quantized_blip`], [`quantized_llama`] and [`quantized_qwen2`].
|
||||
//!
|
||||
//! The implementations aim to be readable while maintaining good performance. For more information
|
||||
//! on each model see the model's module docs in the links below.
|
||||
|
||||
pub mod based;
|
||||
pub mod beit;
|
||||
pub mod bert;
|
||||
|
||||
@ -3,7 +3,11 @@
|
||||
//! Open Contrastive Language-Image Pre-Training (OpenCLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! - [GH Link](https://github.com/mlfoundations/open_clip)
|
||||
//! - 💻 [GH Link](https://github.com/mlfoundations/open_clip)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2212.07143)
|
||||
//!
|
||||
//! ## Overview
|
||||
//!
|
||||
//! 
|
||||
|
||||
pub mod text_model;
|
||||
|
||||
@ -1,17 +1,15 @@
|
||||
//! Persimmon Model
|
||||
//!
|
||||
//! A transformer language model for efficient inference and general-purpose tasks. See Persimmon model details at:
|
||||
//! - [Hugging Face](https://huggingface.co/adept/persimmon-8b-base)
|
||||
//!
|
||||
//! The model uses a standard transformer architecture with:
|
||||
//! A transformer language model for efficient inference and general-purpose tasks. The model uses a standard transformer architecture with:
|
||||
//! - Layer normalization for Q/K attention
|
||||
//! - RoPE embeddings with partial rotary factor
|
||||
//! - ReLU activation
|
||||
//! - Separate number of attention heads and KV heads
|
||||
//!
|
||||
//! References:
|
||||
//! - [Hugging Face Implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/modeling_persimmon.py)
|
||||
//! - [Persimmon Config](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/configuration_persimmon.py)
|
||||
//! - 💻 [Hugging Face Implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/modeling_persimmon.py)
|
||||
//! - 💻 [Persimmon Config](https://github.com/huggingface/transformers/blob/main/src/transformers/models/persimmon/configuration_persimmon.py)
|
||||
//! - 🤗 [Hugging Face](https://huggingface.co/adept/persimmon-8b-base)
|
||||
//!
|
||||
|
||||
use candle::DType;
|
||||
|
||||
@ -1,18 +1,15 @@
|
||||
//! Microsoft Phi model implementation
|
||||
//!
|
||||
//! See Phi model details at:
|
||||
//! - [Phi-2 Model](https://huggingface.co/microsoft/phi-2)
|
||||
//!
|
||||
//! The Phi series are decoder-only transformers designed for code and language tasks.
|
||||
//!
|
||||
//! Key characteristics:
|
||||
//! - Decoder-only transformer architecture
|
||||
//! - RoPE embeddings
|
||||
//! - Layer normalization
|
||||
//! - QK normalization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Hugging Face Implementation](https://huggingface.co/microsoft/phi-2)
|
||||
//! - [Alternative Implementation](https://huggingface.co/microsoft/phi-2/tree/main)
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-phi1-phi2-wasm-demo)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/microsoft/phi-2)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{layer_norm, linear, Embedding, LayerNorm, Linear};
|
||||
|
||||
@ -3,10 +3,10 @@
|
||||
//! Pixtral is an architecture trained for multimodal learning
|
||||
//! using images paired with text descriptions.
|
||||
//!
|
||||
//! - Transformers Python [reference implementation](https://github.com/huggingface/transformers/tree/main/src/transformers/models/pixtral)
|
||||
//! - [Blog Post](https://mistral.ai/news/pixtral-12b/) -
|
||||
//! - [HF Model Card](https://huggingface.co/mistralai/Pixtral-12B-2409) -
|
||||
//! - [HF Community Model Card](https://huggingface.co/mistral-community/pixtral-12b).
|
||||
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/tree/main/src/transformers/models/pixtral)
|
||||
//! - 📝 [Blog Post](https://mistral.ai/news/pixtral-12b/)
|
||||
//! - 🤗 [HF Model Card](https://huggingface.co/mistralai/Pixtral-12B-2409)
|
||||
//! - 🤗 [HF Community Model Card](https://huggingface.co/mistral-community/pixtral-12b)
|
||||
//!
|
||||
//! # Example
|
||||
//!
|
||||
|
||||
@ -10,9 +10,10 @@
|
||||
//! - Optimized memory usage through quantization
|
||||
//! - Configurable model sizes and parameter counts
|
||||
//!
|
||||
//! References:
|
||||
//! - [LLaMA Paper](https://arxiv.org/abs/2302.13971)
|
||||
//! - [LLaMA Model](https://github.com/facebookresearch/llama)
|
||||
//! - 💻 [GH Link](https://github.com/facebookresearch/llama)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2302.13971)
|
||||
//!
|
||||
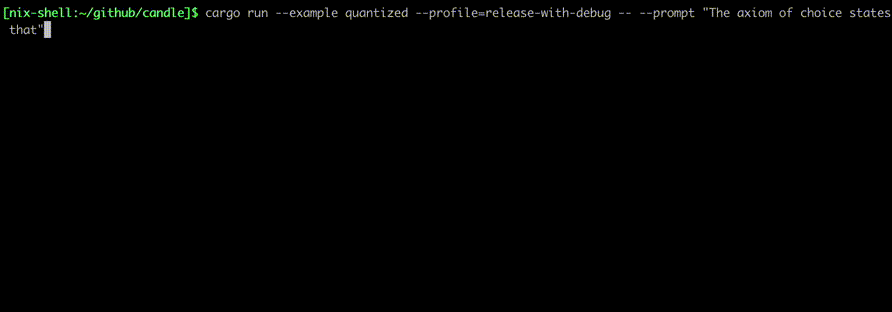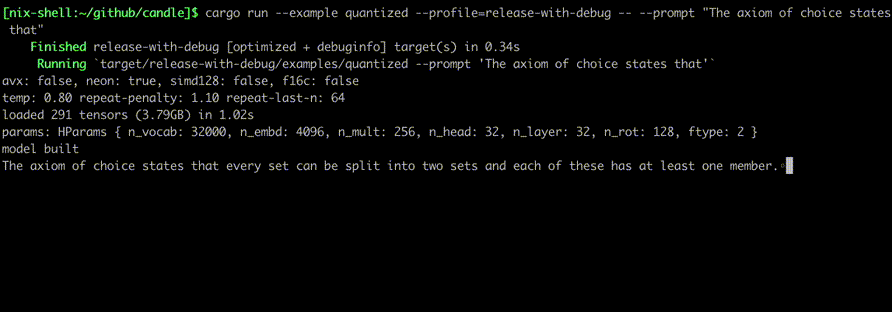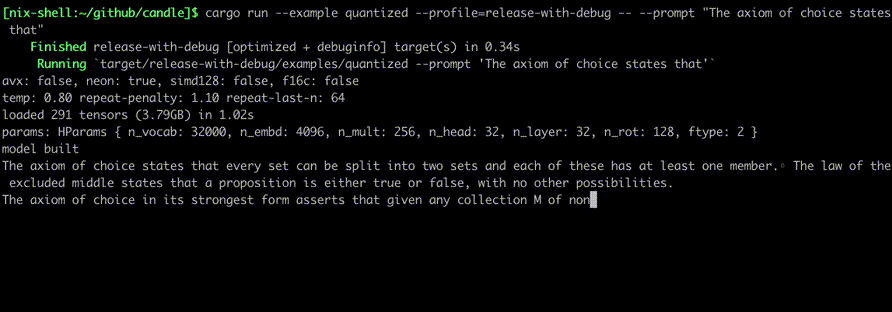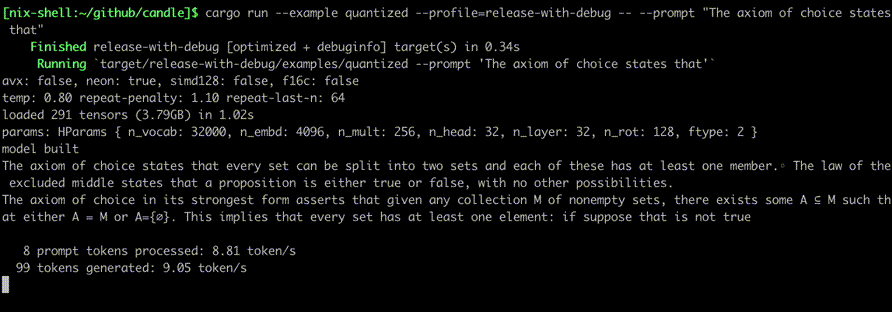
//! 
|
||||
//!
|
||||
|
||||
use std::collections::HashMap;
|
||||
|
||||
@ -11,9 +11,9 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - [Model Card](https://huggingface.co/t5-base)
|
||||
//! - Original model from [T5](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
//! - 📝 [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/t5-base)
|
||||
//! - 🤗 Original model from [T5](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
|
||||
use crate::models::t5::{deserialize_feed_forward_proj_activation, ActivationWithOptionalGating};
|
||||
use crate::models::with_tracing::QMatMul;
|
||||
|
||||
@ -11,8 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Qwen2 Model](https://huggingface.co/Qwen/Qwen2-7B)
|
||||
//! - [Model Card](https://huggingface.co/Qwen/Qwen2-7B)
|
||||
//! - 🤗 [Qwen2 Model](https://huggingface.co/Qwen/Qwen2-7B)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear, linear_no_bias, Linear, RmsNorm};
|
||||
|
||||
@ -1,8 +1,5 @@
|
||||
//! RepVGG inference implementation
|
||||
//!
|
||||
//! See "RepVGG: Making VGG-style ConvNets Great Again" Ding et al. 2021
|
||||
//! https://arxiv.org/abs/2101.03697
|
||||
//!
|
||||
//! Key characteristics:
|
||||
//! - Efficient inference architecture through structural reparameterization
|
||||
//! - Single 3x3 conv layer after fusing 3x3 branch, 1x1 branch and identity branch
|
||||
@ -10,7 +7,7 @@
|
||||
//! - High accuracy with VGG-like plain architecture and training
|
||||
//!
|
||||
//! References:
|
||||
//! - [RepVGG Paper](https://arxiv.org/abs/2101.03697)
|
||||
//! - [RepVGG Paper](https://arxiv.org/abs/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
|
||||
//! - [Official Implementation](https://github.com/DingXiaoH/RepVGG)
|
||||
//!
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! Siglip architecture combining vision and language for zero-shot tasks.
|
||||
//!
|
||||
//! References:
|
||||
//! - [Model Card](https://huggingface.co/google/siglip-base-patch16-224)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/google/siglip-base-patch16-224)
|
||||
//!
|
||||
|
||||
use crate::models::clip::div_l2_norm;
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! Contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! https://github.com/openai/CLIP
|
||||
//! - [CLIP](https://github.com/openai/CLIP)
|
||||
use candle::{DType, Device, Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
use candle_nn::Module;
|
||||
|
||||
@ -104,7 +104,7 @@ impl DDPMScheduler {
|
||||
};
|
||||
let current_beta_t = 1. - alpha_prod_t / alpha_prod_t_prev;
|
||||
|
||||
// For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
|
||||
// For t > 0, compute predicted variance βt (see formula (6) and (7) from [the pdf](https://arxiv.org/pdf/2006.11239.pdf))
|
||||
// and sample from it to get previous sample
|
||||
// x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
|
||||
let variance = (1. - alpha_prod_t_prev) / (1. - alpha_prod_t) * current_beta_t;
|
||||
|
||||
@ -1,12 +1,7 @@
|
||||
//! Ancestral sampling with Euler method steps.
|
||||
//!
|
||||
//! Reference implementation in Rust:
|
||||
//!
|
||||
//! https://github.com/pykeio/diffusers/blob/250b9ad1898af41e76a74c0d8d4292652823338a/src/schedulers/euler_ancestral_discrete.rs
|
||||
//!
|
||||
//! Based on the original [`k-diffusion` implementation by Katherine Crowson][kd].
|
||||
//! Based on the original [`k-diffusion` implementation by Katherine Crowson]( https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72).
|
||||
///
|
||||
/// [kd]: https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72
|
||||
use super::{
|
||||
schedulers::{
|
||||
betas_for_alpha_bar, BetaSchedule, PredictionType, Scheduler, SchedulerConfig,
|
||||
@ -29,7 +24,7 @@ pub struct EulerAncestralDiscreteSchedulerConfig {
|
||||
pub steps_offset: usize,
|
||||
/// prediction type of the scheduler function, one of `epsilon` (predicting
|
||||
/// the noise of the diffusion process), `sample` (directly predicting the noisy sample`)
|
||||
/// or `v_prediction` (see section 2.4 https://imagen.research.google/video/paper.pdf)
|
||||
/// or `v_prediction` (see [section 2.4](https://imagen.research.google/video/paper.pdf))
|
||||
pub prediction_type: PredictionType,
|
||||
/// number of diffusion steps used to train the model
|
||||
pub train_timesteps: usize,
|
||||
|
||||
@ -3,9 +3,9 @@
|
||||
//! Stable Diffusion is a latent text-to-image diffusion model capable of
|
||||
//! generating photo-realistic images given any text input.
|
||||
//!
|
||||
//! - [Original Repository](https://github.com/CompVis/stable-diffusion)
|
||||
//! - [Hugging Face](https://huggingface.co/runwayml/stable-diffusion-v1-5)
|
||||
//! - The default scheduler for the v1.5, v2.1 and XL 1.0 version is the Denoising Diffusion Implicit Model scheduler (DDIM). The original paper and some code can be found in the [associated repo](https://github.com/ermongroup/ddim). The default scheduler for the XL Turbo version is the Euler Ancestral scheduler.
|
||||
//! - 💻 [Original Repository](https://github.com/CompVis/stable-diffusion)
|
||||
//! - 🤗 [Hugging Face](https://huggingface.co/runwayml/stable-diffusion-v1-5)
|
||||
//! - The default scheduler for the v1.5, v2.1 and XL 1.0 version is the Denoising Diffusion Implicit Model scheduler (DDIM). The original paper and some code can be found in the [associated repo](https://github.com/ermongroup/ddim). The default scheduler for the XL Turbo version is the Euler Ancestral scheduler.
|
||||
//!
|
||||
//!
|
||||
//! # Example
|
||||
|
||||
@ -3,7 +3,8 @@
|
||||
//! Some Residual Network blocks used in UNet models.
|
||||
//!
|
||||
//! Denoising Diffusion Implicit Models, K. He and al, 2015.
|
||||
//! https://arxiv.org/abs/1512.03385
|
||||
//! - [Paper](https://arxiv.org/abs/1512.03385)
|
||||
//!
|
||||
use crate::models::with_tracing::{conv2d, Conv2d};
|
||||
use candle::{Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
|
||||
@ -43,7 +43,7 @@ pub enum PredictionType {
|
||||
|
||||
/// Time step spacing for the diffusion process.
|
||||
///
|
||||
/// "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
|
||||
/// "linspace", "leading", "trailing" corresponds to annotation of Table 2. of the [paper](https://arxiv.org/abs/2305.08891)
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
pub enum TimestepSpacing {
|
||||
Leading,
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Support for different model sizes (3B, 7B)
|
||||
//!
|
||||
//! References:
|
||||
//! - [Model Card](https://huggingface.co/stabilityai/stablelm-3b-4e1t)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/stabilityai/stablelm-3b-4e1t)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear, linear_no_bias, Linear};
|
||||
|
||||
@ -11,8 +11,8 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [StarCoder Paper](https://arxiv.org/abs/2305.06161)
|
||||
//! - [Model Card](https://huggingface.co/bigcode/starcoder)
|
||||
//! - 📝 [StarCoder Paper](https://arxiv.org/abs/2305.06161)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/bigcode/starcoder)
|
||||
//!
|
||||
|
||||
use candle::{DType, Device, Module, Result, Tensor, D};
|
||||
|
||||
@ -11,9 +11,10 @@
|
||||
//! - Support for sequence-to-sequence tasks
|
||||
//!
|
||||
//! References:
|
||||
//! - [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - [HuggingFace T5](https://huggingface.co/docs/transformers/model_doc/t5)
|
||||
//! - [GH Model](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-T5-Generation-Wasm)
|
||||
//! - 💻[GH Model](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/docs/transformers/model_doc/t5)
|
||||
//! - 📝 [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//!
|
||||
//! # Encoder-decoder example:
|
||||
//!
|
||||
|
||||
@ -1,10 +1,14 @@
|
||||
//! Whisper Model Implementation
|
||||
//!
|
||||
//! Whisper is an automatic speech recognition (ASR) system trained on large amounts
|
||||
//! of multilingual and multitask supervised data collected from the web.
|
||||
//! of multilingual and multitask supervised data collected from the web. It can be used to
|
||||
//! convert audio files (in the `.wav` format) to text. Supported features include
|
||||
//! language detection as well as multilingual speech recognition.
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-whisper)
|
||||
//! - 💻 [GH Link](https://github.com/openai/whisper)
|
||||
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py)
|
||||
//!
|
||||
//! - [GH Link](https://github.com/openai/whisper)
|
||||
//! - Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py)
|
||||
//!
|
||||
pub mod audio;
|
||||
pub mod model;
|
||||
|
||||
@ -3,10 +3,17 @@
|
||||
//! Würstchen is an efficient diffusion model architecture for generating images using
|
||||
//! a two-stage approach with a small decoder and prior network.
|
||||
//!
|
||||
//! - [Paper Link](https://openreview.net/pdf?id=gU58AyJlYz)
|
||||
//! - [GH Link](https://github.com/dome272/Wuerstchen)
|
||||
//! - [Reference Implementation](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py)
|
||||
//! - 💻 [GH Link](https://github.com/dome272/Wuerstchen)
|
||||
//! - 🤗 [HF Link](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/wuerstchen/pipeline_wuerstchen.py)
|
||||
//! - 📝 [Paper](https://openreview.net/pdf?id=gU58AyJlYz)
|
||||
//!
|
||||
//! ## Example
|
||||
//!
|
||||
//! <div align=center>
|
||||
//! <img src="https://github.com/huggingface/candle/raw/main/candle-examples/examples/wuerstchen/assets/cat.jpg" alt="" width=320>
|
||||
//! <p>"Anthropomorphic cat dressed as a fire fighter"</p>
|
||||
//! </div>
|
||||
|
||||
pub mod attention_processor;
|
||||
pub mod common;
|
||||
pub mod ddpm;
|
||||
|
||||
@ -1,7 +1,12 @@
|
||||
//! Yi model implementation.
|
||||
//!
|
||||
//! Yi is a decoder-only large language model trained by 01.AI.
|
||||
//! It follows a standard transformer architecture similar to Llama.
|
||||
//! This candle implementation uses a pre-trained Yi decoder-only large language model for inference.
|
||||
//! The model was trained by 01.AI and follows a standard transformer architecture similar to LLaMA.
|
||||
//!
|
||||
//! Original code:
|
||||
//! - 💻 [Yi Model](https://huggingface.co/01-ai/Yi-6B)
|
||||
//! - 💻 [Yi Modeling Code](https://huggingface.co/01-ai/Yi-6B/blob/main/modeling_yi.py)
|
||||
//! - 📝 [Technical Report](https://arxiv.org/abs/2403.04652) Yi: Open Foundation Models by 01.AI
|
||||
//!
|
||||
//! Key characteristics:
|
||||
//! - Multi-head attention with rotary positional embeddings
|
||||
@ -9,9 +14,6 @@
|
||||
//! - SwiGLU activation in feed-forward layers
|
||||
//! - Grouped-query attention for efficient inference
|
||||
//!
|
||||
//! References:
|
||||
//! - [Yi Model](https://huggingface.co/01-ai/Yi-6B)
|
||||
//! - [Hugging Face](https://huggingface.co/01-ai/Yi-6B/blob/main/modeling_yi.py)
|
||||
|
||||
use crate::models::with_tracing::{linear_no_bias, Linear, RmsNorm};
|
||||
use candle::{DType, Device, Module, Result, Tensor, D};
|
||||
|
||||
Reference in New Issue
Block a user