mirror of
https://github.com/huggingface/candle.git
synced 2025-06-19 19:58:35 +00:00
Use HF Papers
This commit is contained in:
@ -1,7 +1,7 @@
|
||||
//! Based from the Stanford Hazy Research group.
|
||||
//!
|
||||
//! See "Simple linear attention language models balance the recall-throughput tradeoff", Arora et al. 2024
|
||||
//! - Simple linear attention language models balance the recall-throughput tradeoff. [Arxiv](https://arxiv.org/abs/2402.18668)
|
||||
//! - Simple linear attention language models balance the recall-throughput tradeoff. [Arxiv](https://huggingface.co/papers/2402.18668)
|
||||
//! - [Github Rep](https://github.com/HazyResearch/based)
|
||||
//! - [Blogpost](https://hazyresearch.stanford.edu/blog/2024-03-03-based)
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Based on the BEIT vision-language model.
|
||||
//!
|
||||
//! See "BEIT: BERT Pre-Training of Image Transformers", Bao et al. 2021
|
||||
//! - [Arxiv](https://arxiv.org/abs/2106.08254)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2106.08254)
|
||||
//! - [Github](https://github.com/microsoft/unilm/tree/master/beit)
|
||||
//!
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! Bert is a general large language model that can be used for various language tasks:
|
||||
//! - Compute sentence embeddings for a prompt.
|
||||
//! - Compute similarities between a set of sentences.
|
||||
//! - [Arxiv](https://arxiv.org/abs/1810.04805) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
|
||||
//! - [Arxiv](https://huggingface.co/papers/1810.04805) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
|
||||
//! - Upstream [Github repo](https://github.com/google-research/bert).
|
||||
//! - See bert in [candle-examples](https://github.com/huggingface/candle/tree/main/candle-examples/) for runnable code
|
||||
//!
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! [StarCoder/BigCode](https://huggingface.co/bigcode/starcoderbase-1b) is a LLM
|
||||
//! model specialized to code generation. The initial model was trained on 80
|
||||
//! programming languages. See "StarCoder: A State-of-the-Art LLM for Code", Mukherjee et al. 2023
|
||||
//! - [Arxiv](https://arxiv.org/abs/2305.06161)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2305.06161)
|
||||
//! - [Github](https://github.com/bigcode-project/starcoder)
|
||||
//!
|
||||
//! ## Running some example
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
|
||||
use super::blip_text;
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
//! Implementation of BLIP text encoder/decoder.
|
||||
//!
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
use super::with_tracing::{linear, Embedding, Linear};
|
||||
use candle::{Module, Result, Tensor, D};
|
||||
|
||||
@ -13,9 +13,9 @@ use super::Activation;
|
||||
|
||||
/// Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
|
||||
/// positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
|
||||
/// [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
|
||||
/// [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
|
||||
/// For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
|
||||
/// with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
|
||||
/// with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
|
||||
#[derive(Clone, Debug)]
|
||||
pub enum PositionEmbeddingType {
|
||||
Absolute,
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! A Pre-Trained Model For Code Generation with Multilingual Evaluations on HumanEval-X"
|
||||
//!
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2303.17568)
|
||||
//! - 📝 [Arxiv](https://huggingface.co/papers/2303.17568)
|
||||
//! - 💻 [Github](https://github.com/THUDM/CodeGeeX)
|
||||
//!
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! See "Patches Are All You Need?" by Trockman et al. 2022
|
||||
//!
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2201.09792)
|
||||
//! - 📝 [Arxiv](https://huggingface.co/papers/2201.09792)
|
||||
//! - 💻 [Github](https://github.com/locuslab/convmixer)
|
||||
//!
|
||||
use candle::Result;
|
||||
|
||||
@ -8,8 +8,8 @@
|
||||
//! - 💻 [ConvNeXt](https://github.com/facebookresearch/ConvNeXt/)
|
||||
//! - 💻 [ConvNeXt-V2](https://github.com/facebookresearch/ConvNeXt-V2/)
|
||||
//! - 💻 [timm](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/convnext.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.03545) A ConvNet for the 2020s
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2301.00808) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.03545) A ConvNet for the 2020s
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2301.00808) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
|
||||
//!
|
||||
|
||||
use candle::shape::ShapeWithOneHole;
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! original architecture. This implementation is specifically trained for plant species
|
||||
//! classification on the PlantCLEF2024 dataset with 7,806 classes.
|
||||
//!
|
||||
//! - [Paper](https://arxiv.org/abs/2309.16588). DINOv2: Learning Robust Visual Features without Supervision
|
||||
//! - [Paper](https://huggingface.co/papers/2309.16588). DINOv2: Learning Robust Visual Features without Supervision
|
||||
//! - [GH Repo](https://github.com/facebookresearch/dinov2)
|
||||
//!
|
||||
//! # Example
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Implementation of DistilBert, a distilled version of BERT.
|
||||
//!
|
||||
//! See:
|
||||
//! - ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://arxiv.org/abs/1910.01108)
|
||||
//! - ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://huggingface.co/papers/1910.01108)
|
||||
//!
|
||||
use super::with_tracing::{layer_norm, linear, LayerNorm, Linear};
|
||||
use candle::{DType, Device, Result, Tensor};
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Implementation of EfficientBert, an efficient variant of BERT for computer vision tasks.
|
||||
//!
|
||||
//! See:
|
||||
//! - ["EfficientBERT: Progressively Searching Multilayer Perceptron Architectures for BERT"](https://arxiv.org/abs/2201.00462)
|
||||
//! - ["EfficientBERT: Progressively Searching Multilayer Perceptron Architectures for BERT"](https://huggingface.co/papers/2201.00462)
|
||||
//!
|
||||
use candle::{Context, Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
//! to achieve strong performance while maintaining low memory usage.
|
||||
//!
|
||||
//! The model was originally described in the paper:
|
||||
//! ["EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention"](https://arxiv.org/abs/2305.07027)
|
||||
//! ["EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention"](https://huggingface.co/papers/2305.07027)
|
||||
//!
|
||||
//! This implementation is based on the reference implementation from
|
||||
//! [pytorch-image-models](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/efficientvit_msra.py).
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! EnCodec neural audio codec based on the Encodec implementation.
|
||||
//!
|
||||
//! See ["High Fidelity Neural Audio Compression"](https://arxiv.org/abs/2210.13438)
|
||||
//! See ["High Fidelity Neural Audio Compression"](https://huggingface.co/papers/2210.13438)
|
||||
//!
|
||||
//! Based on implementation from [huggingface/transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/encodec/modeling_encodec.py)
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! The model returns the probability for an image to belong to each of the 1000
|
||||
//! ImageNet categories.
|
||||
//!
|
||||
//! - [Paper](https://arxiv.org/abs/2303.11331). EVA-02: A Visual Representation for Neon Genesis
|
||||
//! - [Paper](https://huggingface.co/papers/2303.11331). EVA-02: A Visual Representation for Neon Genesis
|
||||
//! - [Code](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/eva2.py)
|
||||
//!
|
||||
//! # Example
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! # FastViT inference implementation based on timm
|
||||
//!
|
||||
//! ## Description
|
||||
//! See ["FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"](https://arxiv.org/pdf/2303.14189)
|
||||
//! See ["FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"](https://huggingface.co/papers/2303.14189)
|
||||
//!
|
||||
//! Implementation based on [timm model](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/fastvit.py)
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//!
|
||||
//! - 💻 [Hiera](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/hiera.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2306.00989). Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2306.00989). Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
|
||||
|
||||
use candle::{Result, D};
|
||||
use candle_nn::{conv2d, layer_norm, linear, ops::softmax, Conv2dConfig, Func, VarBuilder};
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA: Open and Efficient Foundation Language Models"](https://arxiv.org/abs/2302.13971)
|
||||
//! See ["LLaMA: Open and Efficient Foundation Language Models"](https://huggingface.co/papers/2302.13971)
|
||||
//!
|
||||
//! Implementation based on Hugging Face's [transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py)
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama2 inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://huggingface.co/papers/2307.09288)
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-llama2)
|
||||
//! - 💻 llama2.c [GH Link](https://github.com/karpathy/llama2.c)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama2 inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://huggingface.co/papers/2307.09288)
|
||||
//!
|
||||
//! Based on the [llama2.c](https://github.com/karpathy/llama2.c) implementation
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! language model (Llama) for multimodal capabilities. The architecture implements the training-free projection technique.
|
||||
//!
|
||||
//! - 💻[GH Link](https://github.com/haotian-liu/LLaVA/tree/main)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2304.08485)/ Visual Instruction Tuning
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2304.08485)/ Visual Instruction Tuning
|
||||
//!
|
||||
|
||||
pub mod config;
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Mamba inference implementation.
|
||||
//!
|
||||
//! See ["Mamba: Linear-Time Sequence Modeling with Selective State Spaces"](https://arxiv.org/abs/2312.00752)
|
||||
//! See ["Mamba: Linear-Time Sequence Modeling with Selective State Spaces"](https://huggingface.co/papers/2312.00752)
|
||||
//!
|
||||
//! Based on reference implementation from the AlbertMamba project
|
||||
//! A fast implementation of mamba for inference only.
|
||||
@ -122,7 +122,7 @@ impl MambaBlock {
|
||||
let proj_for_conv = candle_nn::ops::silu(&proj_for_conv)?;
|
||||
// SSM + Selection, we're doing inference here so only need the last step of
|
||||
// the sequence.
|
||||
// Algorithm 3.2 on page 6, https://arxiv.org/pdf/2312.00752.pdf
|
||||
// Algorithm 3.2 on page 6, https://huggingface.co/papers/2312.00752
|
||||
|
||||
let x_proj = self.x_proj.forward(&proj_for_conv)?;
|
||||
let delta = x_proj.narrow(D::Minus1, 0, self.dt_rank)?.contiguous()?;
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
//! MixFormer (Microsoft's Phi Architecture)
|
||||
//!
|
||||
//! See "Textbooks Are All You Need II: phi-1.5 technical report", Lin et al. 2023
|
||||
//! - [Arxiv](https://arxiv.org/abs/2309.05463)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2309.05463)
|
||||
//! - [Github](https://huggingface.co/microsoft/phi-1_5)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear, Embedding as E, Linear};
|
||||
/// MixFormer model.
|
||||
/// https://huggingface.co/microsoft/phi-1_5
|
||||
/// https://arxiv.org/abs/2309.05463
|
||||
/// https://huggingface.co/papers/2309.05463
|
||||
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
|
||||
use candle_nn::{Activation, VarBuilder};
|
||||
use serde::Deserialize;
|
||||
|
||||
@ -3,14 +3,14 @@
|
||||
//! Mix of Multi-scale Dilated and Traditional Convolutions (MMDiT) is an architecture
|
||||
//! introduced for Stable Diffusion 3, with the MMDiT-X variant used in Stable Diffusion 3.5.
|
||||
//!
|
||||
//! - 📝 [Research Paper](https://arxiv.org/abs/2403.03206)
|
||||
//! - 📝 [Research Paper](https://huggingface.co/papers/2403.03206)
|
||||
//! - 💻 ComfyUI [reference implementation](https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py)
|
||||
//! - 💻 Stability-AI [MMDiT-X implementation](https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py)
|
||||
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
|
||||
pub mod blocks;
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
// Implement the MMDiT model originally introduced for Stable Diffusion 3 (https://arxiv.org/abs/2403.03206),
|
||||
// Implement the MMDiT model originally introduced for Stable Diffusion 3 (https://huggingface.co/papers/2403.03206),
|
||||
// as well as the MMDiT-X variant introduced for Stable Diffusion 3.5-medium (https://huggingface.co/stabilityai/stable-diffusion-3.5-medium)
|
||||
// This follows the implementation of the MMDiT model in the ComfyUI repository.
|
||||
// https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py#L1
|
||||
|
||||
@ -6,12 +6,12 @@
|
||||
//! - Projection layers to align the feature spaces
|
||||
//!
|
||||
//! See model details at:
|
||||
//! - [FastViT](https://arxiv.org/abs/2303.14189)
|
||||
//! - [FastViT](https://huggingface.co/papers/2303.14189)
|
||||
//! - [OpenCLIP](https://github.com/mlfoundations/open_clip)
|
||||
//!
|
||||
//! References:
|
||||
//! - [MobileVLM](https://huggingface.co/mobileVLM)
|
||||
//! - [MetaCLIP](https://arxiv.org/abs/2309.16671)
|
||||
//! - [MetaCLIP](https://huggingface.co/papers/2309.16671)
|
||||
//!
|
||||
|
||||
use super::fastvit;
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//!
|
||||
//! ## Paper
|
||||
//!
|
||||
//! ["MobileNetV4 - Universal Models for the Mobile Ecosystem"](https://arxiv.org/abs/2404.10518)
|
||||
//! ["MobileNetV4 - Universal Models for the Mobile Ecosystem"](https://huggingface.co/papers/2404.10518)
|
||||
//!
|
||||
//! ## References
|
||||
//!
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! MobileOne inference implementation based on timm and candle-repvgg
|
||||
//!
|
||||
//! See ["MobileOne: An Improved One millisecond Mobile Backbone"](https://arxiv.org/abs/2206.04040)
|
||||
//! See ["MobileOne: An Improved One millisecond Mobile Backbone"](https://huggingface.co/papers/2206.04040)
|
||||
|
||||
use candle::{DType, Result, Tensor, D};
|
||||
use candle_nn::{
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! ModernBERT
|
||||
//!
|
||||
//! ModernBERT is a modernized bidirectional encoder-only Transformer model.
|
||||
//! - [Arxiv](https://arxiv.org/abs/2412.13663) "Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference"
|
||||
//! - [Arxiv](https://huggingface.co/papers/2412.13663) "Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference"
|
||||
//! - Upstream [Github repo](https://github.com/AnswerDotAI/ModernBERT).
|
||||
//! - See modernbert in [candle-examples](https://github.com/huggingface/candle/tree/main/candle-examples/) for runnable code
|
||||
//!
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! NV-Embed-v2 is a text embedding model that combines a Mistral decoder with a latent attention mechanism to produce high-quality text embeddings.
|
||||
//!
|
||||
//! This implementation is based on the [paper](https://arxiv.org/pdf/2405.17428) and [weights](https://huggingface.co/nvidia/NV-Embed-v2)
|
||||
//! This implementation is based on the [paper](https://huggingface.co/papers/2405.17428) and [weights](https://huggingface.co/nvidia/NV-Embed-v2)
|
||||
//!
|
||||
//! # Query-Passage Retrieval Example
|
||||
//! ```bash
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! See OLMo 2 model details at:
|
||||
//! - [Hugging Face Collection](https://huggingface.co/collections/allenai/olmo-2-674117b93ab84e98afc72edc)
|
||||
//! - [OLMo 2 Paper](https://arxiv.org/abs/2501.00656)
|
||||
//! - [OLMo 2 Paper](https://huggingface.co/papers/2501.00656)
|
||||
//!
|
||||
//!
|
||||
use candle::{DType, Device, Module, Result, Tensor, D};
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! - 💻 [GH Link](https://github.com/mlfoundations/open_clip)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2212.07143)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2212.07143)
|
||||
//!
|
||||
//! ## Overview
|
||||
//!
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Multimodal multi-purpose model combining Gemma-based language model with SigLIP image understanding
|
||||
//!
|
||||
//! See PaLiGemma details at:
|
||||
//! - [Paper](https://arxiv.org/abs/2402.05257)
|
||||
//! - [Paper](https://huggingface.co/papers/2402.05257)
|
||||
//! - [Google Blog Post](https://blog.research.google/2024/02/paligemma-scaling-language-image.html)
|
||||
//!
|
||||
//! The model is a multimodal combination of:
|
||||
@ -11,7 +11,7 @@
|
||||
//!
|
||||
//! References:
|
||||
//! - [HuggingFace Implementation](https://huggingface.co/google/paligemma-3b)
|
||||
//! - [Paper: PaLI-3 and Beyond: Scaling Language-Image Learning](https://arxiv.org/abs/2402.05257)
|
||||
//! - [Paper: PaLI-3 and Beyond: Scaling Language-Image Learning](https://huggingface.co/papers/2402.05257)
|
||||
//!
|
||||
|
||||
use crate::models::{gemma, siglip};
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [BLIP Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - [BLIP Paper](https://huggingface.co/papers/2201.12086)
|
||||
//! - [Hugging Face Implementation](https://huggingface.co/docs/transformers/model_doc/blip)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Quantized linear transformations
|
||||
//!
|
||||
//! References:
|
||||
//! - [BLIP Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - [BLIP Paper](https://huggingface.co/papers/2201.12086)
|
||||
//! - [Hugging Face Implementation](https://huggingface.co/docs/transformers/model_doc/blip)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Configurable model sizes and parameter counts
|
||||
//!
|
||||
//! - 💻 [GH Link](https://github.com/facebookresearch/llama)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2302.13971)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2302.13971)
|
||||
//!
|
||||
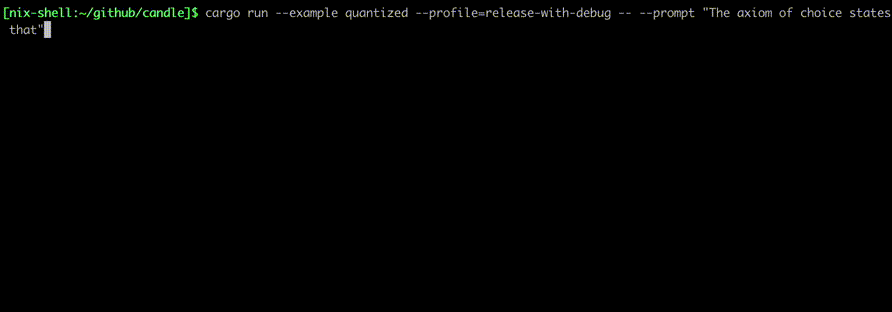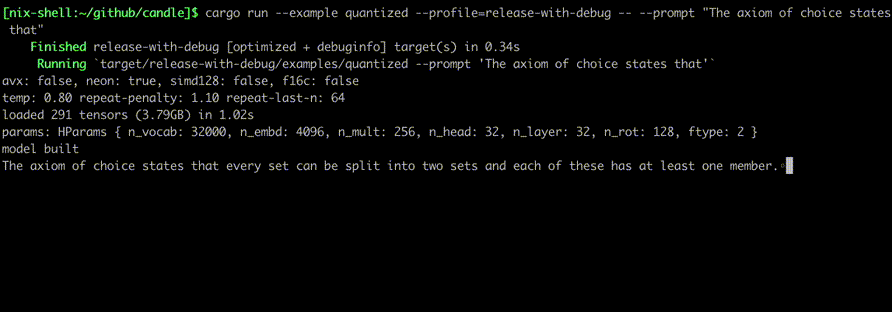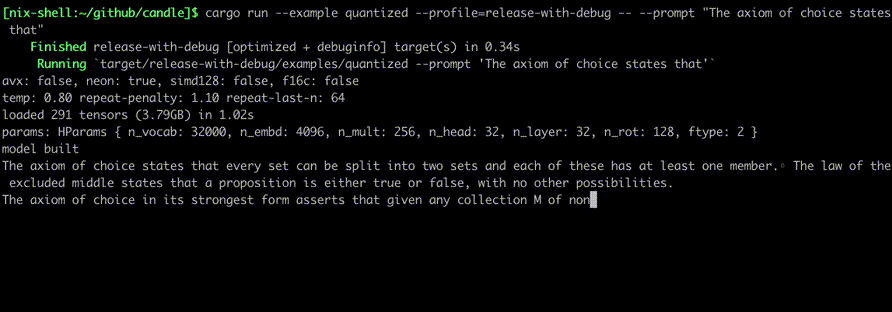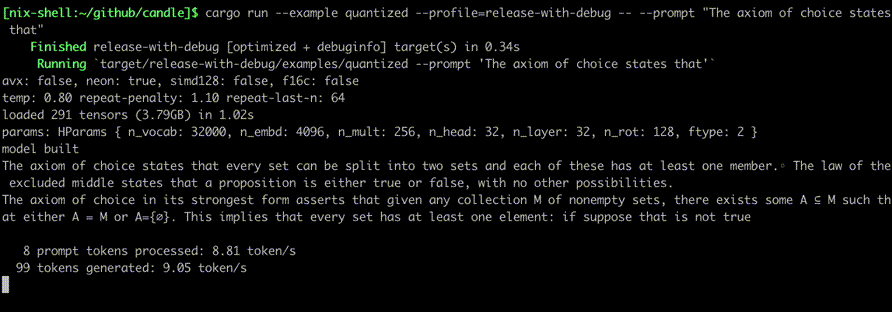
//! 
|
||||
//!
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - 8-bit quantization of weights
|
||||
//!
|
||||
//! References:
|
||||
//! - [LLaMA2 Paper](https://arxiv.org/abs/2307.09288)
|
||||
//! - [LLaMA2 Paper](https://huggingface.co/papers/2307.09288)
|
||||
//! - [LLaMA2 Technical Report](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Mistral Paper](https://arxiv.org/abs/2310.06825)
|
||||
//! - [Mistral Paper](https://huggingface.co/papers/2310.06825)
|
||||
//! - [Model Card](https://huggingface.co/mistralai/Mistral-7B-v0.1)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Phi2 Paper](https://arxiv.org/abs/2309.05463)
|
||||
//! - [Phi2 Paper](https://huggingface.co/papers/2309.05463)
|
||||
//! - [Model Card](https://huggingface.co/microsoft/phi-2)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Gemma Paper](https://arxiv.org/abs/2401.06751)
|
||||
//! - [Gemma Paper](https://huggingface.co/papers/2401.06751)
|
||||
//! - [Model Card](https://ai.google.dev/gemma)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - 📝 [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - 📝 [T5 Paper](https://huggingface.co/papers/1910.10683)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/t5-base)
|
||||
//! - 🤗 Original model from [T5](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
//! - Rotary positional embeddings (RoPE)
|
||||
//!
|
||||
//! References:
|
||||
//! - [Qwen2 Paper](https://arxiv.org/abs/2401.08985)
|
||||
//! - [Qwen2 Paper](https://huggingface.co/papers/2401.08985)
|
||||
//! - [Model Card](https://huggingface.co/Qwen/Qwen2-7B-beta)
|
||||
//!
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
//!
|
||||
//! References:
|
||||
//! - [Gemma: Open Models Based on Gemini Technology](https://blog.google/technology/developers/gemma-open-models/)
|
||||
//! - [Recurrent Memory model architecture](https://arxiv.org/abs/2402.00441)
|
||||
//! - [Recurrent Memory model architecture](https://huggingface.co/papers/2402.00441)
|
||||
//!
|
||||
//! This implementation is based on the python version from huggingface/transformers.
|
||||
//! https://github.com/huggingface/transformers/blob/b109257f4fb8b1166e7c53cc5418632014ed53a5/src/transformers/models/recurrent_gemma/modeling_recurrent_gemma.py#L2
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
//! - High accuracy with VGG-like plain architecture and training
|
||||
//!
|
||||
//! References:
|
||||
//! - [RepVGG Paper](https://arxiv.org/abs/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
|
||||
//! - [RepVGG Paper](https://huggingface.co/papers/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
|
||||
//! - [Official Implementation](https://github.com/DingXiaoH/RepVGG)
|
||||
//!
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//!
|
||||
//! ## Reference
|
||||
//!
|
||||
//! [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
|
||||
//! [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385)
|
||||
//! He et al. (2015)
|
||||
//!
|
||||
//! This paper introduced ResNet, a deep neural network architecture that utilizes
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Lightweight all-MLP decode head
|
||||
//!
|
||||
//! References:
|
||||
//! - [SegFormer Paper](https://arxiv.org/abs/2105.15203)
|
||||
//! - [SegFormer Paper](https://huggingface.co/papers/2105.15203)
|
||||
//! - [Model Card](https://huggingface.co/nvidia/mit-b0)
|
||||
//!
|
||||
|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/candle-segment-anything-wasm)
|
||||
//! - 💻 [GH Link](https://github.com/facebookresearch/segment-anything)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2304.02643)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2304.02643)
|
||||
//! - 💡 The default backbone can be replaced by the smaller and faster TinyViT model based on [MobileSAM](https://github.com/ChaoningZhang/MobileSAM).
|
||||
//!
|
||||
//!
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! See: [SNAC](https://github.com/hubertsiuzdak/snac)
|
||||
//!
|
||||
/// Multi-Scale Neural Audio Codec (SNAC) compresses audio into discrete codes at a low bitrate.
|
||||
/// For more information, read the paper: https://arxiv.org/abs/2410.14411
|
||||
/// For more information, read the paper: https://huggingface.co/papers/2410.14411
|
||||
///
|
||||
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
|
||||
use candle_nn::{
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
//! this to non-Markovian guidance.
|
||||
//!
|
||||
//! Denoising Diffusion Implicit Models, J. Song et al, 2020.
|
||||
//! https://arxiv.org/abs/2010.02502
|
||||
//! https://huggingface.co/papers/2010.02502
|
||||
use super::schedulers::{
|
||||
betas_for_alpha_bar, BetaSchedule, PredictionType, Scheduler, SchedulerConfig, TimestepSpacing,
|
||||
};
|
||||
|
||||
@ -104,7 +104,7 @@ impl DDPMScheduler {
|
||||
};
|
||||
let current_beta_t = 1. - alpha_prod_t / alpha_prod_t_prev;
|
||||
|
||||
// For t > 0, compute predicted variance βt (see formula (6) and (7) from [the pdf](https://arxiv.org/pdf/2006.11239.pdf))
|
||||
// For t > 0, compute predicted variance βt (see formula (6) and (7) from [the pdf](https://huggingface.co/papers/2006.11239))
|
||||
// and sample from it to get previous sample
|
||||
// x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
|
||||
let variance = (1. - alpha_prod_t_prev) / (1. - alpha_prod_t) * current_beta_t;
|
||||
@ -112,7 +112,7 @@ impl DDPMScheduler {
|
||||
// retrieve variance
|
||||
match self.config.variance_type {
|
||||
DDPMVarianceType::FixedSmall => variance.max(1e-20),
|
||||
// for rl-diffuser https://arxiv.org/abs/2205.09991
|
||||
// for rl-diffuser https://huggingface.co/papers/2205.09991
|
||||
DDPMVarianceType::FixedSmallLog => {
|
||||
let variance = variance.max(1e-20).ln();
|
||||
(variance * 0.5).exp()
|
||||
@ -166,12 +166,12 @@ impl DDPMScheduler {
|
||||
}
|
||||
|
||||
// 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
|
||||
// See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
|
||||
// See formula (7) from https://huggingface.co/papers/2006.11239
|
||||
let pred_original_sample_coeff = (alpha_prod_t_prev.sqrt() * current_beta_t) / beta_prod_t;
|
||||
let current_sample_coeff = current_alpha_t.sqrt() * beta_prod_t_prev / beta_prod_t;
|
||||
|
||||
// 5. Compute predicted previous sample µ_t
|
||||
// See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
|
||||
// See formula (7) from https://huggingface.co/papers/2006.11239
|
||||
let pred_prev_sample = ((&pred_original_sample * pred_original_sample_coeff)?
|
||||
+ sample * current_sample_coeff)?;
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! Some Residual Network blocks used in UNet models.
|
||||
//!
|
||||
//! Denoising Diffusion Implicit Models, K. He and al, 2015.
|
||||
//! - [Paper](https://arxiv.org/abs/1512.03385)
|
||||
//! - [Paper](https://huggingface.co/papers/1512.03385)
|
||||
//!
|
||||
use crate::models::with_tracing::{conv2d, Conv2d};
|
||||
use candle::{Result, Tensor, D};
|
||||
|
||||
@ -43,7 +43,7 @@ pub enum PredictionType {
|
||||
|
||||
/// Time step spacing for the diffusion process.
|
||||
///
|
||||
/// "linspace", "leading", "trailing" corresponds to annotation of Table 2. of the [paper](https://arxiv.org/abs/2305.08891)
|
||||
/// "linspace", "leading", "trailing" corresponds to annotation of Table 2. of the [paper](https://huggingface.co/papers/2305.08891)
|
||||
#[derive(Debug, Clone, Copy)]
|
||||
pub enum TimestepSpacing {
|
||||
Leading,
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//!
|
||||
//! For more information, see the original publication:
|
||||
//! UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models, W. Zhao et al, 2023.
|
||||
//! https://arxiv.org/abs/2302.04867
|
||||
//! https://huggingface.co/papers/2302.04867
|
||||
//!
|
||||
//! This work is based largely on UniPC implementation from the diffusers python package:
|
||||
//! https://raw.githubusercontent.com/huggingface/diffusers/e8aacda762e311505ba05ae340af23b149e37af3/src/diffusers/schedulers/scheduling_unipc_multistep.py
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - 📝 [StarCoder Paper](https://arxiv.org/abs/2305.06161)
|
||||
//! - 📝 [StarCoder Paper](https://huggingface.co/papers/2305.06161)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/bigcode/starcoder)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Rotary positional embeddings (RoPE)
|
||||
//!
|
||||
//! References:
|
||||
//! - [MRL Framework](https://arxiv.org/abs/2205.13147)
|
||||
//! - [MRL Framework](https://huggingface.co/papers/2205.13147)
|
||||
//! - [Model Card](https://huggingface.co/dunzhang/stella_en_1.5B_v5)
|
||||
//!
|
||||
|
||||
@ -56,7 +56,7 @@ pub struct Config {
|
||||
}
|
||||
|
||||
// Excerpt from `stella` model card:
|
||||
// `Stella_en_1.5B_v5` models have been trained on [MRL](https://arxiv.org/abs/2205.13147) enabling multiple output dimensions
|
||||
// `Stella_en_1.5B_v5` models have been trained on [MRL](https://huggingface.co/papers/2205.13147) enabling multiple output dimensions
|
||||
// Embed head represents the config for various embedding dims supported
|
||||
#[derive(Debug, Default, Clone, PartialEq, serde::Deserialize)]
|
||||
pub struct EmbedHead {
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-T5-Generation-Wasm)
|
||||
//! - 💻[GH Model](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/docs/transformers/model_doc/t5)
|
||||
//! - 📝 [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - 📝 [T5 Paper](https://huggingface.co/papers/1910.10683)
|
||||
//!
|
||||
//! # Encoder-decoder example:
|
||||
//!
|
||||
@ -33,7 +33,7 @@
|
||||
//! # Translation with MADLAD
|
||||
//!
|
||||
//!
|
||||
//! [MADLAD-400](https://arxiv.org/abs/2309.04662) is a series of multilingual machine translation T5 models trained on 250 billion tokens covering over 450 languages using publicly available data. These models are competitive with significantly larger models.
|
||||
//! [MADLAD-400](https://huggingface.co/papers/2309.04662) is a series of multilingual machine translation T5 models trained on 250 billion tokens covering over 450 languages using publicly available data. These models are competitive with significantly larger models.
|
||||
//!
|
||||
//! ```bash
|
||||
//! cargo run --example t5 --release -- \
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Layer normalization and self-attention
|
||||
//!
|
||||
//! References:
|
||||
//! - [Paper](https://arxiv.org/abs/2109.10282)
|
||||
//! - [Paper](https://huggingface.co/papers/2109.10282)
|
||||
//! - [Model Card](https://huggingface.co/microsoft/trocr-base-handwritten)
|
||||
//!
|
||||
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - ReLU activation and dropout
|
||||
//!
|
||||
//! References:
|
||||
//! - [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
|
||||
//! - [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://huggingface.co/papers/1409.1556)
|
||||
//!
|
||||
|
||||
use candle::{ModuleT, Result, Tensor};
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Layer normalization
|
||||
//!
|
||||
//! References:
|
||||
//! - [ViT Paper](https://arxiv.org/abs/2010.11929)
|
||||
//! - [ViT Paper](https://huggingface.co/papers/2010.11929)
|
||||
//! - [Model Card](https://huggingface.co/google/vit-base-patch16-224)
|
||||
//!
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
//! Original code:
|
||||
//! - 💻 [Yi Model](https://huggingface.co/01-ai/Yi-6B)
|
||||
//! - 💻 [Yi Modeling Code](https://huggingface.co/01-ai/Yi-6B/blob/main/modeling_yi.py)
|
||||
//! - 📝 [Technical Report](https://arxiv.org/abs/2403.04652) Yi: Open Foundation Models by 01.AI
|
||||
//! - 📝 [Technical Report](https://huggingface.co/papers/2403.04652) Yi: Open Foundation Models by 01.AI
|
||||
//!
|
||||
//! Key characteristics:
|
||||
//! - Multi-head attention with rotary positional embeddings
|
||||
|
||||
Reference in New Issue
Block a user