mirror of
https://github.com/huggingface/candle.git
synced 2025-06-16 10:38:54 +00:00
Compare commits
12 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| ed353eb76d | |||
| ffb8d63324 | |||
| 92106c8762 | |||
| 9ce4fe6194 | |||
| 450a49ed1a | |||
| 6bd61727bc | |||
| 485ddf2996 | |||
| 36508a2c93 | |||
| 3d05f5cf3d | |||
| 637473cb5e | |||
| e27b4700ad | |||
| 1fdfb58de5 |
@ -43,7 +43,7 @@ candle-onnx = { path = "./candle-onnx", version = "0.9.1" }
|
||||
candle-transformers = { path = "./candle-transformers", version = "0.9.1" }
|
||||
clap = { version = "4.2.4", features = ["derive"] }
|
||||
criterion = { version = "0.5.1", default-features=false }
|
||||
cudarc = { version = "0.16.1", features = ["std", "cublas", "cublaslt", "curand", "driver", "nvrtc", "f16", "cuda-version-from-build-system", "dynamic-linking"], default-features=false }
|
||||
cudarc = { version = "0.16.3", features = ["std", "cublas", "cublaslt", "curand", "driver", "nvrtc", "f16", "cuda-version-from-build-system", "dynamic-linking"], default-features=false }
|
||||
fancy-regex = "0.13.0"
|
||||
gemm = { version = "0.17.0", features = ["wasm-simd128-enable"] }
|
||||
hf-hub = "0.4.1"
|
||||
|
||||
@ -483,7 +483,11 @@ impl<I: IntDType> Map1 for Gather<'_, I> {
|
||||
let start_dst_idx = start_dst_idx + i * dst_right_len;
|
||||
for right_i in 0..dst_right_len {
|
||||
let dst_idx = start_dst_idx + right_i;
|
||||
let index = ids[dst_idx].as_usize();
|
||||
let index = ids[dst_idx];
|
||||
if index == I::max_value() {
|
||||
dst[dst_idx] = T::zero();
|
||||
} else {
|
||||
let index = index.as_usize();
|
||||
if index >= src_dim_len {
|
||||
Err(Error::InvalidIndex {
|
||||
index,
|
||||
@ -497,6 +501,7 @@ impl<I: IntDType> Map1 for Gather<'_, I> {
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
Ok(dst)
|
||||
}
|
||||
}
|
||||
@ -535,7 +540,12 @@ impl<I: IntDType> Map1 for IndexSelect<'_, I> {
|
||||
let start_src_idx = left_i * right_len * src_dim;
|
||||
let start_dst_idx = left_i * right_len * n_ids;
|
||||
for i in 0..n_ids {
|
||||
let index = self.ids[self.ids_l.start_offset() + stride_ids * i].as_usize();
|
||||
let start_dst_idx = start_dst_idx + i * right_len;
|
||||
let index = self.ids[self.ids_l.start_offset() + stride_ids * i];
|
||||
if index == I::max_value() {
|
||||
dst[start_dst_idx..start_dst_idx + right_len].fill(T::zero());
|
||||
} else {
|
||||
let index = index.as_usize();
|
||||
if index >= src_dim {
|
||||
Err(Error::InvalidIndex {
|
||||
index,
|
||||
@ -545,11 +555,11 @@ impl<I: IntDType> Map1 for IndexSelect<'_, I> {
|
||||
.bt())?
|
||||
}
|
||||
let start_src_idx = start_src_idx + index * right_len;
|
||||
let start_dst_idx = start_dst_idx + i * right_len;
|
||||
dst[start_dst_idx..start_dst_idx + right_len]
|
||||
.copy_from_slice(&src[start_src_idx..start_src_idx + right_len])
|
||||
}
|
||||
}
|
||||
}
|
||||
Ok(dst)
|
||||
}
|
||||
}
|
||||
@ -631,7 +641,11 @@ impl<I: IntDType, M: ElemUpdate> Map2InPlace for Scatter<'_, I, M> {
|
||||
let start_ids_idx = start_ids_idx + i * ids_right_len;
|
||||
for right_i in 0..dst_right_len {
|
||||
let ids_idx = start_ids_idx + right_i;
|
||||
let index = ids[ids_idx].as_usize();
|
||||
let index = ids[ids_idx];
|
||||
if index == I::max_value() {
|
||||
continue;
|
||||
}
|
||||
let index = index.as_usize();
|
||||
if index >= dst_dim_len {
|
||||
Err(Error::InvalidIndex {
|
||||
index,
|
||||
@ -674,6 +688,9 @@ impl<I: IntDType> Map2 for IndexAdd<'_, I> {
|
||||
let post_dim = src_l.dims()[dim + 1..].iter().product::<usize>();
|
||||
if dim == 0 {
|
||||
for (src_idx, dst_idx) in self.ids.iter().enumerate() {
|
||||
if *dst_idx == I::max_value() {
|
||||
continue;
|
||||
}
|
||||
let dst_idx = dst_idx.as_usize();
|
||||
if dst_idx >= max_idx {
|
||||
Err(Error::InvalidIndex {
|
||||
@ -692,6 +709,9 @@ impl<I: IntDType> Map2 for IndexAdd<'_, I> {
|
||||
}
|
||||
} else {
|
||||
for (src_idx, dst_idx) in self.ids.iter().enumerate() {
|
||||
if *dst_idx == I::max_value() {
|
||||
continue;
|
||||
}
|
||||
let dst_idx = dst_idx.as_usize();
|
||||
if dst_idx >= max_idx {
|
||||
Err(Error::InvalidIndex {
|
||||
|
||||
@ -180,7 +180,7 @@ with_dtype!(bf16, BF16, bf16::from_f64, bf16::to_f64);
|
||||
with_dtype!(f32, F32, |v: f64| v as f32, |v: f32| v as f64);
|
||||
with_dtype!(f64, F64, |v: f64| v, |v: f64| v);
|
||||
|
||||
pub trait IntDType: WithDType {
|
||||
pub trait IntDType: WithDType + num_traits::Bounded {
|
||||
fn is_true(&self) -> bool;
|
||||
fn as_usize(&self) -> usize;
|
||||
}
|
||||
|
||||
@ -845,6 +845,9 @@ fn embeddings(device: &Device) -> Result<()> {
|
||||
assert_eq!(hs.to_vec2::<f32>()?, &[[0.0, 1.0], [4.0, 5.0], [2.0, 3.0]]);
|
||||
let hs = t.index_select(&ids.to_dtype(DType::I64)?, 0)?;
|
||||
assert_eq!(hs.to_vec2::<f32>()?, &[[0.0, 1.0], [4.0, 5.0], [2.0, 3.0]]);
|
||||
let ids = Tensor::new(&[u32::MAX, 2u32, u32::MAX], device)?;
|
||||
let hs = t.index_select(&ids, 0)?;
|
||||
assert_eq!(hs.to_vec2::<f32>()?, &[[0.0, 0.0], [4.0, 5.0], [0.0, 0.0]]);
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@ -1087,6 +1090,31 @@ fn scatter(device: &Device) -> Result<()> {
|
||||
[1.0, 1.0, 1.0]
|
||||
]
|
||||
);
|
||||
|
||||
let hs = {
|
||||
let ids = Tensor::new(
|
||||
&[
|
||||
[0u32, u32::MAX, 2],
|
||||
[3, 4, u32::MAX],
|
||||
[3, 3, 1],
|
||||
[u32::MAX, u32::MAX, 4],
|
||||
],
|
||||
device,
|
||||
)?;
|
||||
init.scatter(&ids, &t, 0)?
|
||||
};
|
||||
assert_eq!(
|
||||
hs.to_vec2::<f32>()?,
|
||||
&[
|
||||
[0.0, 1.0, 1.0],
|
||||
[1.0, 1.0, 8.0],
|
||||
[1.0, 1.0, 2.0],
|
||||
[6.0, 7.0, 1.0],
|
||||
[1.0, 4.0, 11.0],
|
||||
[1.0, 1.0, 1.0]
|
||||
]
|
||||
);
|
||||
|
||||
init.scatter_set(&ids, &t, 0)?;
|
||||
assert_eq!(
|
||||
init.to_vec2::<f32>()?,
|
||||
@ -1099,6 +1127,7 @@ fn scatter(device: &Device) -> Result<()> {
|
||||
[1.0, 1.0, 1.0]
|
||||
]
|
||||
);
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@ -1132,6 +1161,23 @@ fn gather(device: &Device) -> Result<()> {
|
||||
let hs = t.gather(&ids, 0)?;
|
||||
assert_eq!(hs.to_vec2::<f32>()?, &[[0.0, 7.0, 2.0], [0.0, 4.0, 5.0]]);
|
||||
|
||||
let hs = {
|
||||
let ids = Tensor::new(
|
||||
&[
|
||||
[0u32, 0u32],
|
||||
[2u32, u32::MAX],
|
||||
[u32::MAX, 1u32],
|
||||
[0u32, 2u32],
|
||||
],
|
||||
device,
|
||||
)?;
|
||||
t.gather(&ids, 1)?
|
||||
};
|
||||
assert_eq!(
|
||||
hs.to_vec2::<f32>()?,
|
||||
&[[0.0, 0.0], [5.0, 0.0], [0.0, 7.0], [9.0, 11.0]]
|
||||
);
|
||||
|
||||
// Random data
|
||||
|
||||
// Dim: 0
|
||||
|
||||
@ -16,10 +16,9 @@ fn read_u32<T: Read>(reader: &mut T) -> std::io::Result<u32> {
|
||||
fn check_magic_number<T: Read>(reader: &mut T, expected: u32) -> Result<()> {
|
||||
let magic_number = read_u32(reader)?;
|
||||
if magic_number != expected {
|
||||
Err(io::Error::new(
|
||||
io::ErrorKind::Other,
|
||||
format!("incorrect magic number {magic_number} != {expected}"),
|
||||
))?;
|
||||
Err(io::Error::other(format!(
|
||||
"incorrect magic number {magic_number} != {expected}"
|
||||
)))?;
|
||||
}
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@ -4,7 +4,7 @@ Experimental, not instruction-tuned small LLM from the Hazy Research group, comb
|
||||
|
||||
[Blogpost](https://hazyresearch.stanford.edu/blog/2024-03-03-based)
|
||||
|
||||
[Simple linear attention language models balance the recall-throughput tradeoff](https://arxiv.org/abs/2402.18668)
|
||||
[Simple linear attention language models balance the recall-throughput tradeoff](https://huggingface.co/papers/2402.18668)
|
||||
|
||||
## Running an example
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-beit
|
||||
|
||||
[Beit](https://arxiv.org/abs/2106.08254) is a computer vision model.
|
||||
[Beit](https://huggingface.co/papers/2106.08254) is a computer vision model.
|
||||
In this example, it is used as an ImageNet classifier: the model returns the
|
||||
probability for the image to belong to each of the 1000 ImageNet categories.
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
A lightweight CNN architecture that processes image patches similar to a vision transformer, with separate spatial and channel convolutions.
|
||||
|
||||
ConvMixer from [Patches Are All You Need?](https://arxiv.org/pdf/2201.09792) and [ConvMixer](https://github.com/locuslab/convmixer).
|
||||
ConvMixer from [Patches Are All You Need?](https://huggingface.co/papers/2201.09792) and [ConvMixer](https://github.com/locuslab/convmixer).
|
||||
|
||||
## Running an example
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# candle-convnext
|
||||
|
||||
[A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) and
|
||||
[ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808).
|
||||
[A ConvNet for the 2020s](https://huggingface.co/papers/2201.03545) and
|
||||
[ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://huggingface.co/papers/2301.00808).
|
||||
|
||||
This candle implementation uses a pre-trained ConvNeXt network for inference. The
|
||||
classification head has been trained on the ImageNet dataset and returns the
|
||||
|
||||
@ -20,8 +20,8 @@ use hf_hub::{api::sync::Api, Repo, RepoType};
|
||||
use tokenizers::{Encoding, PaddingParams, Tokenizer};
|
||||
|
||||
enum TaskType {
|
||||
Ner(DebertaV2NERModel),
|
||||
TextClassification(DebertaV2SeqClassificationModel),
|
||||
Ner(Box<DebertaV2NERModel>),
|
||||
TextClassification(Box<DebertaV2SeqClassificationModel>),
|
||||
}
|
||||
|
||||
#[derive(Parser, Debug, Clone, ValueEnum)]
|
||||
@ -169,21 +169,16 @@ impl Args {
|
||||
|
||||
match self.task {
|
||||
ArgsTask::Ner => Ok((
|
||||
TaskType::Ner(DebertaV2NERModel::load(
|
||||
vb,
|
||||
&config,
|
||||
Some(id2label.clone()),
|
||||
)?),
|
||||
TaskType::Ner(DebertaV2NERModel::load(vb, &config, Some(id2label.clone()))?.into()),
|
||||
config,
|
||||
tokenizer,
|
||||
id2label,
|
||||
)),
|
||||
ArgsTask::TextClassification => Ok((
|
||||
TaskType::TextClassification(DebertaV2SeqClassificationModel::load(
|
||||
vb,
|
||||
&config,
|
||||
Some(id2label.clone()),
|
||||
)?),
|
||||
TaskType::TextClassification(
|
||||
DebertaV2SeqClassificationModel::load(vb, &config, Some(id2label.clone()))?
|
||||
.into(),
|
||||
),
|
||||
config,
|
||||
tokenizer,
|
||||
id2label,
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-dinov2-reg4
|
||||
|
||||
[DINOv2-reg4](https://arxiv.org/abs/2309.16588) is the lastest version of DINOv2 with registers.
|
||||
[DINOv2-reg4](https://huggingface.co/papers/2309.16588) is the lastest version of DINOv2 with registers.
|
||||
In this example, it is used as an plant species classifier: the model returns the
|
||||
probability for the image to belong to each of the 7806 PlantCLEF2024 categories.
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
//! DINOv2 reg4 finetuned on PlantCLEF 2024
|
||||
//! https://arxiv.org/abs/2309.16588
|
||||
//! https://huggingface.co/papers/2309.16588
|
||||
//! https://huggingface.co/spaces/BVRA/PlantCLEF2024
|
||||
//! https://zenodo.org/records/10848263
|
||||
|
||||
|
||||
@ -16,8 +16,8 @@ use std::path::PathBuf;
|
||||
use tokenizers::Tokenizer;
|
||||
|
||||
enum ModelType {
|
||||
Masked(DistilBertForMaskedLM),
|
||||
UnMasked(DistilBertModel),
|
||||
Masked(Box<DistilBertForMaskedLM>),
|
||||
UnMasked(Box<DistilBertModel>),
|
||||
}
|
||||
|
||||
impl ModelType {
|
||||
@ -144,10 +144,12 @@ impl Args {
|
||||
|
||||
fn create_model(&self, config: &Config, vb: VarBuilder) -> Result<ModelType> {
|
||||
match self.model {
|
||||
Which::DistilbertForMaskedLM => {
|
||||
Ok(ModelType::Masked(DistilBertForMaskedLM::load(vb, config)?))
|
||||
}
|
||||
Which::DistilBert => Ok(ModelType::UnMasked(DistilBertModel::load(vb, config)?)),
|
||||
Which::DistilbertForMaskedLM => Ok(ModelType::Masked(
|
||||
DistilBertForMaskedLM::load(vb, config)?.into(),
|
||||
)),
|
||||
Which::DistilBert => Ok(ModelType::UnMasked(
|
||||
DistilBertModel::load(vb, config)?.into(),
|
||||
)),
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! EfficientNet implementation.
|
||||
//!
|
||||
//! https://arxiv.org/abs/1905.11946
|
||||
//! https://huggingface.co/papers/1905.11946
|
||||
|
||||
#[cfg(feature = "mkl")]
|
||||
extern crate intel_mkl_src;
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-efficientvit
|
||||
|
||||
[EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention](https://arxiv.org/abs/2305.07027).
|
||||
[EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention](https://huggingface.co/papers/2305.07027).
|
||||
|
||||
This candle implementation uses a pre-trained EfficientViT (from Microsoft Research Asia) network for inference.
|
||||
The classification head has been trained on the ImageNet dataset and returns the probabilities for the top-5 classes.
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-eva2
|
||||
|
||||
[EVA-02](https://arxiv.org/abs/2303.11331) is a computer vision model.
|
||||
[EVA-02](https://huggingface.co/papers/2303.11331) is a computer vision model.
|
||||
In this example, it is used as an ImageNet classifier: the model returns the
|
||||
probability for the image to belong to each of the 1000 ImageNet categories.
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-fastvit
|
||||
|
||||
[FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization](https://arxiv.org/abs/2303.14189).
|
||||
[FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization](https://huggingface.co/papers/2303.14189).
|
||||
This candle implementation uses a pre-trained FastViT network for inference. The
|
||||
classification head has been trained on the ImageNet dataset and returns the
|
||||
probabilities for the top-5 classes.
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
gte-Qwen1.5-7B-instruct is a variant of the GTE embedding model family.
|
||||
|
||||
- [Model card](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) on the HuggingFace Hub.
|
||||
- [Technical report](https://arxiv.org/abs/2308.03281) *Towards General Text Embeddings with Multi-stage Contrastive Learning*
|
||||
- [Technical report](https://huggingface.co/papers/2308.03281) *Towards General Text Embeddings with Multi-stage Contrastive Learning*
|
||||
|
||||
|
||||
## Running the example
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# hiera
|
||||
|
||||
[Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989)
|
||||
[Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://huggingface.co/papers/2306.00989)
|
||||
This candle implementation uses pre-trained Hiera models from timm for inference.
|
||||
The classification head has been trained on the ImageNet dataset and returns the probabilities for the top-5 classes.
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ the transformer architecture. It leverages State Space Models (SSMs) with the
|
||||
goal of being computationally efficient on long sequences. The implementation is
|
||||
based on [mamba.rs](https://github.com/LaurentMazare/mamba.rs).
|
||||
|
||||
- [1]. [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752).
|
||||
- [1]. [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://huggingface.co/papers/2312.00752).
|
||||
|
||||
Compared to the mamba-minimal example, this version is far more efficient but
|
||||
would only work for inference.
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
MobileCLIP is family of efficient CLIP-like models using FastViT-based image encoders.
|
||||
|
||||
See [MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training](https://arxiv.org/abs/2311.17049)
|
||||
See [MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training](https://huggingface.co/papers/2311.17049)
|
||||
|
||||
|
||||
## Running on an example on cpu
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-mobilenetv4
|
||||
|
||||
[MobileNetV4 - Universal Models for the Mobile Ecosystem](https://arxiv.org/abs/2404.10518)
|
||||
[MobileNetV4 - Universal Models for the Mobile Ecosystem](https://huggingface.co/papers/2404.10518)
|
||||
This candle implementation uses pre-trained MobileNetV4 models from timm for inference.
|
||||
The classification head has been trained on the ImageNet dataset and returns the probabilities for the top-5 classes.
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-mobileone
|
||||
|
||||
[MobileOne: An Improved One millisecond Mobile Backbone](https://arxiv.org/abs/2206.04040).
|
||||
[MobileOne: An Improved One millisecond Mobile Backbone](https://huggingface.co/papers/2206.04040).
|
||||
|
||||
This candle implementation uses a pre-trained MobileOne network for inference. The
|
||||
classification head has been trained on the ImageNet dataset and returns the
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-musicgen
|
||||
|
||||
Candle implementation of musicgen from [Simple and Controllable Music Generation](https://arxiv.org/pdf/2306.05284).
|
||||
Candle implementation of musicgen from [Simple and Controllable Music Generation](https://huggingface.co/papers/2306.05284).
|
||||
|
||||
## Running an example
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
OLMo is a series of Open Language Models designed to enable the science of language models.
|
||||
|
||||
- **Project Page:** https://allenai.org/olmo
|
||||
- **Paper:** [Link](https://arxiv.org/abs/2402.00838)
|
||||
- **Papers:** [OLMo](https://huggingface.co/papers/2402.00838) [OLMo 2](https://huggingface.co/papers/2501.00656)
|
||||
- **Technical blog post:** https://blog.allenai.org/olmo-open-language-model-87ccfc95f580
|
||||
- **W&B Logs:** https://wandb.ai/ai2-llm/OLMo-1B/reports/OLMo-1B--Vmlldzo2NzY1Njk1
|
||||
<!-- - **Press release:** TODO -->
|
||||
|
||||
@ -8,6 +8,7 @@ use anyhow::{Error as E, Result};
|
||||
use clap::{Parser, ValueEnum};
|
||||
|
||||
use candle_transformers::models::olmo::{Config, Model as OLMo};
|
||||
use candle_transformers::models::olmo2::{Config as Config2, Model as OLMo2};
|
||||
|
||||
use candle::{DType, Device, Tensor};
|
||||
use candle_examples::token_output_stream::TokenOutputStream;
|
||||
@ -18,6 +19,7 @@ use tokenizers::Tokenizer;
|
||||
|
||||
enum Model {
|
||||
OLMo(OLMo),
|
||||
OLMo2(OLMo2),
|
||||
}
|
||||
|
||||
struct TextGeneration {
|
||||
@ -82,6 +84,7 @@ impl TextGeneration {
|
||||
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
|
||||
let logits = match &mut self.model {
|
||||
Model::OLMo(m) => m.forward(&input, start_pos)?,
|
||||
Model::OLMo2(m) => m.forward(&input, start_pos)?,
|
||||
};
|
||||
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
|
||||
let logits = if self.repeat_penalty == 1. {
|
||||
@ -129,6 +132,8 @@ enum Which {
|
||||
W7bTwin2T,
|
||||
#[value(name = "1.7-7b")]
|
||||
V1_7W7b,
|
||||
#[value(name = "2-1b")]
|
||||
V2W1b,
|
||||
}
|
||||
|
||||
#[derive(Parser, Debug)]
|
||||
@ -220,6 +225,7 @@ fn main() -> Result<()> {
|
||||
Which::W7b => "allenai/OLMo-7B-hf".to_string(),
|
||||
Which::W7bTwin2T => "allenai/OLMo-7B-Twin-2T-hf".to_string(),
|
||||
Which::V1_7W7b => "allenai/OLMo-1.7-7B-hf".to_string(),
|
||||
Which::V2W1b => "allenai/OLMo-2-0425-1B-Instruct".to_string(),
|
||||
},
|
||||
};
|
||||
|
||||
@ -238,33 +244,36 @@ fn main() -> Result<()> {
|
||||
.map(std::path::PathBuf::from)
|
||||
.collect::<Vec<_>>(),
|
||||
None => match args.model {
|
||||
Which::W1b => {
|
||||
Which::W1b | Which::V2W1b => {
|
||||
vec![repo.get("model.safetensors")?]
|
||||
}
|
||||
_ => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
|
||||
},
|
||||
};
|
||||
|
||||
println!("retrieved the files in {:?}", start.elapsed());
|
||||
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
|
||||
|
||||
let start = std::time::Instant::now();
|
||||
let config = {
|
||||
let config_filename = repo.get("config.json")?;
|
||||
let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;
|
||||
config
|
||||
};
|
||||
println!("retrieved the files in {:?}", start.elapsed());
|
||||
|
||||
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
|
||||
let start = std::time::Instant::now();
|
||||
let device = candle_examples::device(args.cpu)?;
|
||||
let model = {
|
||||
let dtype = if device.is_cuda() {
|
||||
DType::BF16
|
||||
} else {
|
||||
DType::F32
|
||||
};
|
||||
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
|
||||
let model = match args.model {
|
||||
Which::W1b | Which::W7b | Which::W7bTwin2T | Which::V1_7W7b => {
|
||||
let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;
|
||||
let model = OLMo::new(&config, vb)?;
|
||||
Model::OLMo(model)
|
||||
}
|
||||
Which::V2W1b => {
|
||||
let config: Config2 = serde_json::from_slice(&std::fs::read(config_filename)?)?;
|
||||
let model = OLMo2::new(&config, vb)?;
|
||||
Model::OLMo2(model)
|
||||
}
|
||||
};
|
||||
|
||||
println!("loaded the model in {:?}", start.elapsed());
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
This example demonstrates how to run [ONNX](https://github.com/onnx/onnx) based models in Candle.
|
||||
|
||||
It contains small variants of two models, [SqueezeNet](https://arxiv.org/pdf/1602.07360.pdf) (default) and [EfficientNet](https://arxiv.org/pdf/1905.11946.pdf).
|
||||
It contains small variants of two models, [SqueezeNet](https://huggingface.co/papers/1602.07360) (default) and [EfficientNet](https://huggingface.co/papers/1905.11946).
|
||||
|
||||
You can run the examples with following commands:
|
||||
|
||||
|
||||
@ -5,12 +5,14 @@ extern crate intel_mkl_src;
|
||||
extern crate accelerate_src;
|
||||
|
||||
use candle::{IndexOp, D};
|
||||
use candle_examples::save_image;
|
||||
use clap::{Parser, ValueEnum};
|
||||
|
||||
#[derive(Clone, Copy, Debug, ValueEnum)]
|
||||
enum Which {
|
||||
SqueezeNet,
|
||||
EfficientNet,
|
||||
EsrGan,
|
||||
}
|
||||
|
||||
#[derive(Parser)]
|
||||
@ -28,10 +30,21 @@ struct Args {
|
||||
|
||||
pub fn main() -> anyhow::Result<()> {
|
||||
let args = Args::parse();
|
||||
let image = candle_examples::imagenet::load_image224(args.image)?;
|
||||
let image = match args.which {
|
||||
Which::SqueezeNet | Which::EfficientNet => {
|
||||
candle_examples::imagenet::load_image224(&args.image)?
|
||||
}
|
||||
Which::EsrGan => candle_examples::imagenet::load_image_with_std_mean(
|
||||
&args.image,
|
||||
128,
|
||||
&[0.0f32, 0.0, 0.0],
|
||||
&[1.0f32, 1.0, 1.0],
|
||||
)?,
|
||||
};
|
||||
let image = match args.which {
|
||||
Which::SqueezeNet => image,
|
||||
Which::EfficientNet => image.permute((1, 2, 0))?,
|
||||
Which::EsrGan => image,
|
||||
};
|
||||
|
||||
println!("loaded image {image:?}");
|
||||
@ -45,6 +58,9 @@ pub fn main() -> anyhow::Result<()> {
|
||||
Which::EfficientNet => hf_hub::api::sync::Api::new()?
|
||||
.model("onnx/EfficientNet-Lite4".into())
|
||||
.get("efficientnet-lite4-11.onnx")?,
|
||||
Which::EsrGan => hf_hub::api::sync::Api::new()?
|
||||
.model("qualcomm/Real-ESRGAN-x4plus".into())
|
||||
.get("Real-ESRGAN-x4plus.onnx")?,
|
||||
},
|
||||
};
|
||||
|
||||
@ -57,7 +73,11 @@ pub fn main() -> anyhow::Result<()> {
|
||||
let prs = match args.which {
|
||||
Which::SqueezeNet => candle_nn::ops::softmax(&output, D::Minus1)?,
|
||||
Which::EfficientNet => output,
|
||||
Which::EsrGan => output,
|
||||
};
|
||||
|
||||
match args.which {
|
||||
Which::EfficientNet | Which::SqueezeNet => {
|
||||
let prs = prs.i(0)?.to_vec1::<f32>()?;
|
||||
|
||||
// Sort the predictions and take the top 5
|
||||
@ -73,6 +93,21 @@ pub fn main() -> anyhow::Result<()> {
|
||||
p * 100.0
|
||||
);
|
||||
}
|
||||
}
|
||||
Which::EsrGan => {
|
||||
let max_pixel_val = candle::Tensor::try_from(255.0f32)?
|
||||
.to_device(prs.device())?
|
||||
.broadcast_as(prs.shape())?;
|
||||
let out = (prs * max_pixel_val)?.i(0)?.to_dtype(candle::DType::U8)?;
|
||||
|
||||
let pb = std::path::PathBuf::from(args.image);
|
||||
let input_file_name = pb.file_name().unwrap();
|
||||
let mut output_file_name = std::ffi::OsString::from("super_");
|
||||
output_file_name.push(input_file_name);
|
||||
|
||||
save_image(&out, output_file_name)?;
|
||||
}
|
||||
}
|
||||
|
||||
Ok(())
|
||||
}
|
||||
|
||||
@ -8,4 +8,8 @@
|
||||
cargo run --example quantized-qwen2-instruct --release -- --prompt "Write a function to count prime numbers up to N."
|
||||
```
|
||||
|
||||
0.5b, 1.5b, 7b and 72b models are available via `--model` argument.
|
||||
0.5b, 1.5b, 7b and 72b models are available via `--which` argument.
|
||||
|
||||
```bash
|
||||
cargo run --release --example quantized-qwen2-instruct -- --which 0.5b --prompt "Write a function to count prime numbers up to N."
|
||||
```
|
||||
|
||||
17
candle-examples/examples/quantized-qwen3/README.md
Normal file
17
candle-examples/examples/quantized-qwen3/README.md
Normal file
@ -0,0 +1,17 @@
|
||||
# candle-quantized-qwen3
|
||||
|
||||
[Qwen3]((https://qwenlm.github.io/blog/qwen3/)) is an upgraded version of Qwen2.5, released by Alibaba Cloud.
|
||||
|
||||
## Running the example
|
||||
|
||||
```bash
|
||||
cargo run --example quantized-qwen3 --release -- --prompt "Write a function to count prime numbers up to N."
|
||||
```
|
||||
|
||||
|
||||
0.6b is used by default, 1.7b, 4b, 8b, 14b, and 32b models are available via `--which` argument.
|
||||
|
||||
```bash
|
||||
cargo run --example quantized-qwen3 --release -- --which 4b --prompt "A train is travelling at 120mph, how far does it travel in 3 minutes 30 seconds?"
|
||||
```
|
||||
|
||||
314
candle-examples/examples/quantized-qwen3/main.rs
Normal file
314
candle-examples/examples/quantized-qwen3/main.rs
Normal file
@ -0,0 +1,314 @@
|
||||
#[cfg(feature = "mkl")]
|
||||
extern crate intel_mkl_src;
|
||||
|
||||
#[cfg(feature = "accelerate")]
|
||||
extern crate accelerate_src;
|
||||
|
||||
use clap::{Parser, ValueEnum};
|
||||
use std::io::Write;
|
||||
use tokenizers::Tokenizer;
|
||||
|
||||
use candle::quantized::gguf_file;
|
||||
use candle::Tensor;
|
||||
use candle_transformers::generation::{LogitsProcessor, Sampling};
|
||||
|
||||
use candle_examples::token_output_stream::TokenOutputStream;
|
||||
use candle_transformers::models::quantized_qwen3::ModelWeights as Qwen3;
|
||||
|
||||
const DEFAULT_PROMPT: &str = "Write a Rust function to calculate the factorial of a given number.";
|
||||
|
||||
#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]
|
||||
enum Which {
|
||||
#[value(name = "0.6b")]
|
||||
W3_0_6b,
|
||||
#[value(name = "1.7b")]
|
||||
W3_1_7b,
|
||||
#[value(name = "4b")]
|
||||
W3_4b,
|
||||
#[value(name = "8b")]
|
||||
W3_8b,
|
||||
#[value(name = "14b")]
|
||||
W3_14b,
|
||||
#[value(name = "32b")]
|
||||
W3_32b,
|
||||
}
|
||||
|
||||
#[derive(Parser, Debug)]
|
||||
#[command(author, version, about, long_about = None)]
|
||||
struct Args {
|
||||
/// GGUF file to load, typically a .gguf file generated by the quantize command from llama.cpp
|
||||
#[arg(long)]
|
||||
model: Option<String>,
|
||||
|
||||
/// The initial prompt, use 'interactive' for entering multiple prompts in an interactive way
|
||||
/// and 'chat' for an interactive model where history of previous prompts and generated tokens
|
||||
/// is preserved.
|
||||
#[arg(long)]
|
||||
prompt: Option<String>,
|
||||
|
||||
/// The length of the sample to generate (in tokens).
|
||||
#[arg(short = 'n', long, default_value_t = 1000)]
|
||||
sample_len: usize,
|
||||
|
||||
/// The tokenizer config in json format.
|
||||
#[arg(long)]
|
||||
tokenizer: Option<String>,
|
||||
|
||||
/// The temperature used to generate samples, use 0 for greedy sampling.
|
||||
#[arg(long, default_value_t = 0.8)]
|
||||
temperature: f64,
|
||||
|
||||
/// Nucleus sampling probability cutoff.
|
||||
#[arg(long)]
|
||||
top_p: Option<f64>,
|
||||
|
||||
/// Only sample among the top K samples.
|
||||
#[arg(long)]
|
||||
top_k: Option<usize>,
|
||||
|
||||
/// The seed to use when generating random samples.
|
||||
#[arg(long, default_value_t = 299792458)]
|
||||
seed: u64,
|
||||
|
||||
/// Enable tracing (generates a trace-timestamp.json file).
|
||||
#[arg(long)]
|
||||
tracing: bool,
|
||||
|
||||
/// Process prompt elements separately.
|
||||
#[arg(long)]
|
||||
split_prompt: bool,
|
||||
|
||||
/// Run on CPU rather than GPU even if a GPU is available.
|
||||
#[arg(long)]
|
||||
cpu: bool,
|
||||
|
||||
/// Penalty to be applied for repeating tokens, 1. means no penalty.
|
||||
#[arg(long, default_value_t = 1.1)]
|
||||
repeat_penalty: f32,
|
||||
|
||||
/// The context size to consider for the repeat penalty.
|
||||
#[arg(long, default_value_t = 64)]
|
||||
repeat_last_n: usize,
|
||||
|
||||
/// The model size to use.
|
||||
#[arg(long, default_value = "0.6b")]
|
||||
which: Which,
|
||||
}
|
||||
|
||||
impl Args {
|
||||
fn tokenizer(&self) -> anyhow::Result<Tokenizer> {
|
||||
let tokenizer_path = match &self.tokenizer {
|
||||
Some(config) => std::path::PathBuf::from(config),
|
||||
None => {
|
||||
let api = hf_hub::api::sync::Api::new()?;
|
||||
let repo = match self.which {
|
||||
Which::W3_0_6b => "Qwen/Qwen3-0.6B",
|
||||
Which::W3_1_7b => "Qwen/Qwen3-1.7B",
|
||||
Which::W3_4b => "Qwen/Qwen3-4B",
|
||||
Which::W3_8b => "Qwen/Qwen3-8B",
|
||||
Which::W3_14b => "Qwen/Qwen3-14B",
|
||||
Which::W3_32b => "Qwen/Qwen3-32B",
|
||||
};
|
||||
let api = api.model(repo.to_string());
|
||||
api.get("tokenizer.json")?
|
||||
}
|
||||
};
|
||||
Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg)
|
||||
}
|
||||
|
||||
fn model(&self) -> anyhow::Result<std::path::PathBuf> {
|
||||
let model_path = match &self.model {
|
||||
Some(config) => std::path::PathBuf::from(config),
|
||||
None => {
|
||||
let (repo, filename, revision) = match self.which {
|
||||
Which::W3_0_6b => ("unsloth/Qwen3-0.6B-GGUF", "Qwen3-0.6B-Q4_K_M.gguf", "main"),
|
||||
Which::W3_1_7b => ("unsloth/Qwen3-1.7B-GGUF", "Qwen3-1.7B-Q4_K_M.gguf", "main"),
|
||||
Which::W3_4b => ("unsloth/Qwen3-4B-GGUF", "Qwen3-4B-Q4_K_M.gguf", "main"),
|
||||
Which::W3_8b => ("unsloth/Qwen3-8B-GGUF", "Qwen3-8B-Q4_K_M.gguf", "main"),
|
||||
Which::W3_14b => ("unsloth/Qwen3-14B-GGUF", "Qwen3-14B-Q4_K_M.gguf", "main"),
|
||||
Which::W3_32b => ("unsloth/Qwen3-32B-GGUF", "Qwen3-32B-Q4_K_M.gguf", "main"),
|
||||
};
|
||||
let api = hf_hub::api::sync::Api::new()?;
|
||||
api.repo(hf_hub::Repo::with_revision(
|
||||
repo.to_string(),
|
||||
hf_hub::RepoType::Model,
|
||||
revision.to_string(),
|
||||
))
|
||||
.get(filename)?
|
||||
}
|
||||
};
|
||||
Ok(model_path)
|
||||
}
|
||||
}
|
||||
|
||||
fn format_size(size_in_bytes: usize) -> String {
|
||||
if size_in_bytes < 1_000 {
|
||||
format!("{}B", size_in_bytes)
|
||||
} else if size_in_bytes < 1_000_000 {
|
||||
format!("{:.2}KB", size_in_bytes as f64 / 1e3)
|
||||
} else if size_in_bytes < 1_000_000_000 {
|
||||
format!("{:.2}MB", size_in_bytes as f64 / 1e6)
|
||||
} else {
|
||||
format!("{:.2}GB", size_in_bytes as f64 / 1e9)
|
||||
}
|
||||
}
|
||||
|
||||
fn main() -> anyhow::Result<()> {
|
||||
use tracing_chrome::ChromeLayerBuilder;
|
||||
use tracing_subscriber::prelude::*;
|
||||
|
||||
let args = Args::parse();
|
||||
let _guard = if args.tracing {
|
||||
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
|
||||
tracing_subscriber::registry().with(chrome_layer).init();
|
||||
Some(guard)
|
||||
} else {
|
||||
None
|
||||
};
|
||||
|
||||
println!(
|
||||
"avx: {}, neon: {}, simd128: {}, f16c: {}",
|
||||
candle::utils::with_avx(),
|
||||
candle::utils::with_neon(),
|
||||
candle::utils::with_simd128(),
|
||||
candle::utils::with_f16c()
|
||||
);
|
||||
println!(
|
||||
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
|
||||
args.temperature, args.repeat_penalty, args.repeat_last_n
|
||||
);
|
||||
|
||||
let model_path = args.model()?;
|
||||
let mut file = std::fs::File::open(&model_path)?;
|
||||
let start = std::time::Instant::now();
|
||||
let device = candle_examples::device(args.cpu)?;
|
||||
|
||||
let mut model = {
|
||||
let model = gguf_file::Content::read(&mut file).map_err(|e| e.with_path(model_path))?;
|
||||
let mut total_size_in_bytes = 0;
|
||||
for (_, tensor) in model.tensor_infos.iter() {
|
||||
let elem_count = tensor.shape.elem_count();
|
||||
total_size_in_bytes +=
|
||||
elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.block_size();
|
||||
}
|
||||
println!(
|
||||
"loaded {:?} tensors ({}) in {:.2}s",
|
||||
model.tensor_infos.len(),
|
||||
&format_size(total_size_in_bytes),
|
||||
start.elapsed().as_secs_f32(),
|
||||
);
|
||||
Qwen3::from_gguf(model, &mut file, &device)?
|
||||
};
|
||||
println!("model built");
|
||||
|
||||
let tokenizer = args.tokenizer()?;
|
||||
let mut tos = TokenOutputStream::new(tokenizer);
|
||||
let prompt_str = args
|
||||
.prompt
|
||||
.clone()
|
||||
.unwrap_or_else(|| DEFAULT_PROMPT.to_string());
|
||||
|
||||
let prompt_str = format!("<|im_start|>user\n{prompt_str}<|im_end|>\n<|im_start|>assistant\n");
|
||||
print!("formatted prompt: {}", &prompt_str);
|
||||
|
||||
let tokens = tos
|
||||
.tokenizer()
|
||||
.encode(prompt_str, true)
|
||||
.map_err(anyhow::Error::msg)?;
|
||||
|
||||
let tokens = tokens.get_ids();
|
||||
|
||||
let to_sample = args.sample_len.saturating_sub(1);
|
||||
|
||||
let mut all_tokens = vec![];
|
||||
|
||||
let mut logits_processor = {
|
||||
let temperature = args.temperature;
|
||||
let sampling = if temperature <= 0. {
|
||||
Sampling::ArgMax
|
||||
} else {
|
||||
match (args.top_k, args.top_p) {
|
||||
(None, None) => Sampling::All { temperature },
|
||||
(Some(k), None) => Sampling::TopK { k, temperature },
|
||||
(None, Some(p)) => Sampling::TopP { p, temperature },
|
||||
(Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },
|
||||
}
|
||||
};
|
||||
LogitsProcessor::from_sampling(args.seed, sampling)
|
||||
};
|
||||
|
||||
let start_prompt_processing = std::time::Instant::now();
|
||||
|
||||
let mut next_token = if !args.split_prompt {
|
||||
let input = Tensor::new(tokens, &device)?.unsqueeze(0)?;
|
||||
let logits = model.forward(&input, 0)?;
|
||||
let logits = logits.squeeze(0)?;
|
||||
logits_processor.sample(&logits)?
|
||||
} else {
|
||||
let mut next_token = 0;
|
||||
for (pos, token) in tokens.iter().enumerate() {
|
||||
let input = Tensor::new(&[*token], &device)?.unsqueeze(0)?;
|
||||
let logits = model.forward(&input, pos)?;
|
||||
let logits = logits.squeeze(0)?;
|
||||
next_token = logits_processor.sample(&logits)?
|
||||
}
|
||||
next_token
|
||||
};
|
||||
|
||||
let prompt_dt = start_prompt_processing.elapsed();
|
||||
|
||||
all_tokens.push(next_token);
|
||||
|
||||
if let Some(t) = tos.next_token(next_token)? {
|
||||
print!("{t}");
|
||||
std::io::stdout().flush()?;
|
||||
}
|
||||
|
||||
let eos_token = *tos.tokenizer().get_vocab(true).get("<|im_end|>").unwrap();
|
||||
|
||||
let start_post_prompt = std::time::Instant::now();
|
||||
|
||||
let mut sampled = 0;
|
||||
for index in 0..to_sample {
|
||||
let input = Tensor::new(&[next_token], &device)?.unsqueeze(0)?;
|
||||
let logits = model.forward(&input, tokens.len() + index)?;
|
||||
let logits = logits.squeeze(0)?;
|
||||
let logits = if args.repeat_penalty == 1. {
|
||||
logits
|
||||
} else {
|
||||
let start_at = all_tokens.len().saturating_sub(args.repeat_last_n);
|
||||
candle_transformers::utils::apply_repeat_penalty(
|
||||
&logits,
|
||||
args.repeat_penalty,
|
||||
&all_tokens[start_at..],
|
||||
)?
|
||||
};
|
||||
next_token = logits_processor.sample(&logits)?;
|
||||
all_tokens.push(next_token);
|
||||
if let Some(t) = tos.next_token(next_token)? {
|
||||
print!("{t}");
|
||||
std::io::stdout().flush()?;
|
||||
}
|
||||
sampled += 1;
|
||||
if next_token == eos_token {
|
||||
break;
|
||||
};
|
||||
}
|
||||
|
||||
if let Some(rest) = tos.decode_rest().map_err(candle::Error::msg)? {
|
||||
print!("{rest}");
|
||||
}
|
||||
|
||||
std::io::stdout().flush()?;
|
||||
let dt = start_post_prompt.elapsed();
|
||||
println!(
|
||||
"\n\n{:4} prompt tokens processed: {:.2} token/s",
|
||||
tokens.len(),
|
||||
tokens.len() as f64 / prompt_dt.as_secs_f64(),
|
||||
);
|
||||
println!(
|
||||
"{sampled:4} tokens generated: {:.2} token/s",
|
||||
sampled as f64 / dt.as_secs_f64(),
|
||||
);
|
||||
Ok(())
|
||||
}
|
||||
@ -51,7 +51,7 @@ cargo run --example quantized-t5 --release -- \
|
||||
Note that a storm surge is what forecasters consider a hurricane's most dangerous part.
|
||||
```
|
||||
|
||||
### [MADLAD-400](https://arxiv.org/abs/2309.04662)
|
||||
### [MADLAD-400](https://huggingface.co/papers/2309.04662)
|
||||
|
||||
MADLAD-400 is a series of multilingual machine translation T5 models trained on 250 billion tokens covering over 450 languages using publicly available data. These models are competitive with significantly larger models.
|
||||
|
||||
|
||||
@ -9,6 +9,7 @@ use clap::Parser;
|
||||
|
||||
use candle_transformers::models::qwen2::{Config as ConfigBase, ModelForCausalLM as ModelBase};
|
||||
use candle_transformers::models::qwen2_moe::{Config as ConfigMoe, Model as ModelMoe};
|
||||
use candle_transformers::models::qwen3::{Config as Config3, ModelForCausalLM as Model3};
|
||||
|
||||
use candle::{DType, Device, Tensor};
|
||||
use candle_examples::token_output_stream::TokenOutputStream;
|
||||
@ -20,6 +21,7 @@ use tokenizers::Tokenizer;
|
||||
enum Model {
|
||||
Base(ModelBase),
|
||||
Moe(ModelMoe),
|
||||
Base3(Model3),
|
||||
}
|
||||
|
||||
impl Model {
|
||||
@ -27,6 +29,7 @@ impl Model {
|
||||
match self {
|
||||
Self::Moe(ref mut m) => m.forward(xs, s),
|
||||
Self::Base(ref mut m) => m.forward(xs, s),
|
||||
Self::Base3(ref mut m) => m.forward(xs, s),
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -85,6 +88,10 @@ impl TextGeneration {
|
||||
Some(token) => token,
|
||||
None => anyhow::bail!("cannot find the <|endoftext|> token"),
|
||||
};
|
||||
let eos_token2 = match self.tokenizer.get_token("<|im_end|>") {
|
||||
Some(token) => token,
|
||||
None => anyhow::bail!("cannot find the <|im_end|> token"),
|
||||
};
|
||||
let start_gen = std::time::Instant::now();
|
||||
for index in 0..sample_len {
|
||||
let context_size = if index > 0 { 1 } else { tokens.len() };
|
||||
@ -107,7 +114,7 @@ impl TextGeneration {
|
||||
let next_token = self.logits_processor.sample(&logits)?;
|
||||
tokens.push(next_token);
|
||||
generated_tokens += 1;
|
||||
if next_token == eos_token {
|
||||
if next_token == eos_token || next_token == eos_token2 {
|
||||
break;
|
||||
}
|
||||
if let Some(t) = self.tokenizer.next_token(next_token)? {
|
||||
@ -152,6 +159,14 @@ enum WhichModel {
|
||||
W2_7b,
|
||||
#[value(name = "2-72b")]
|
||||
W2_72b,
|
||||
#[value(name = "3-0.6b")]
|
||||
W3_0_6b,
|
||||
#[value(name = "3-1.7b")]
|
||||
W3_1_7b,
|
||||
#[value(name = "3-4b")]
|
||||
W3_4b,
|
||||
#[value(name = "3-8b")]
|
||||
W3_8b,
|
||||
}
|
||||
|
||||
#[derive(Parser, Debug)]
|
||||
@ -254,6 +269,10 @@ fn main() -> Result<()> {
|
||||
WhichModel::W14b => ("1.5", "14B"),
|
||||
WhichModel::W72b => ("1.5", "72B"),
|
||||
WhichModel::MoeA27b => ("1.5", "MoE-A2.7B"),
|
||||
WhichModel::W3_0_6b => ("3", "0.6B"),
|
||||
WhichModel::W3_1_7b => ("3", "1.7B"),
|
||||
WhichModel::W3_4b => ("3", "4B"),
|
||||
WhichModel::W3_8b => ("3", "8B"),
|
||||
};
|
||||
format!("Qwen/Qwen{version}-{size}")
|
||||
}
|
||||
@ -273,7 +292,11 @@ fn main() -> Result<()> {
|
||||
.map(std::path::PathBuf::from)
|
||||
.collect::<Vec<_>>(),
|
||||
None => match args.model {
|
||||
WhichModel::W0_5b | WhichModel::W2_0_5b | WhichModel::W2_1_5b | WhichModel::W1_8b => {
|
||||
WhichModel::W0_5b
|
||||
| WhichModel::W2_0_5b
|
||||
| WhichModel::W2_1_5b
|
||||
| WhichModel::W1_8b
|
||||
| WhichModel::W3_0_6b => {
|
||||
vec![repo.get("model.safetensors")?]
|
||||
}
|
||||
WhichModel::W4b
|
||||
@ -282,7 +305,10 @@ fn main() -> Result<()> {
|
||||
| WhichModel::W14b
|
||||
| WhichModel::W72b
|
||||
| WhichModel::W2_72b
|
||||
| WhichModel::MoeA27b => {
|
||||
| WhichModel::MoeA27b
|
||||
| WhichModel::W3_1_7b
|
||||
| WhichModel::W3_4b
|
||||
| WhichModel::W3_8b => {
|
||||
candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?
|
||||
}
|
||||
},
|
||||
@ -304,6 +330,10 @@ fn main() -> Result<()> {
|
||||
let config: ConfigMoe = serde_json::from_slice(&std::fs::read(config_file)?)?;
|
||||
Model::Moe(ModelMoe::new(&config, vb)?)
|
||||
}
|
||||
WhichModel::W3_0_6b | WhichModel::W3_1_7b | WhichModel::W3_4b | WhichModel::W3_8b => {
|
||||
let config: Config3 = serde_json::from_slice(&std::fs::read(config_file)?)?;
|
||||
Model::Base3(Model3::new(&config, vb)?)
|
||||
}
|
||||
_ => {
|
||||
let config: ConfigBase = serde_json::from_slice(&std::fs::read(config_file)?)?;
|
||||
Model::Base(ModelBase::new(&config, vb)?)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-repvgg
|
||||
|
||||
[RepVGG: Making VGG-style ConvNets Great Again](https://arxiv.org/abs/2101.03697).
|
||||
[RepVGG: Making VGG-style ConvNets Great Again](https://huggingface.co/papers/2101.03697).
|
||||
|
||||
This candle implementation uses a pre-trained RepVGG network for inference. The
|
||||
classification head has been trained on the ImageNet dataset and returns the
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-resnet
|
||||
|
||||
A candle implementation of inference using a pre-trained [ResNet](https://arxiv.org/abs/1512.03385).
|
||||
A candle implementation of inference using a pre-trained [ResNet](https://huggingface.co/papers/1512.03385).
|
||||
This uses a classification head trained on the ImageNet dataset and returns the
|
||||
probabilities for the top-5 classes.
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
Stable Diffusion 3 Medium is a text-to-image model based on Multimodal Diffusion Transformer (MMDiT) architecture.
|
||||
|
||||
- [huggingface repo](https://huggingface.co/stabilityai/stable-diffusion-3-medium)
|
||||
- [research paper](https://arxiv.org/pdf/2403.03206)
|
||||
- [research paper](https://huggingface.co/papers/2403.03206)
|
||||
- [announcement blog post](https://stability.ai/news/stable-diffusion-3-medium)
|
||||
|
||||
Stable Diffusion 3.5 is a family of text-to-image models with latest improvements:
|
||||
|
||||
@ -69,7 +69,7 @@ pub fn euler_sample(
|
||||
}
|
||||
|
||||
// The "Resolution-dependent shifting of timestep schedules" recommended in the SD3 tech report paper
|
||||
// https://arxiv.org/pdf/2403.03206
|
||||
// https://huggingface.co/papers/2403.03206
|
||||
// Following the implementation in ComfyUI:
|
||||
// https://github.com/comfyanonymous/ComfyUI/blob/3c60ecd7a83da43d694e26a77ca6b93106891251/
|
||||
// comfy/model_sampling.py#L181
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# candle-starcoder2
|
||||
|
||||
Candle implementation of Star Coder 2 family of code generation model from [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/pdf/2402.19173).
|
||||
Candle implementation of Star Coder 2 family of code generation model from [StarCoder 2 and The Stack v2: The Next Generation](https://huggingface.co/papers/2402.19173).
|
||||
|
||||
## Running an example
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@ $ cargo run --example stella-en-v5 --release -- --query "What are safetensors?"
|
||||
> Tensor[[1, 1024], f32]
|
||||
```
|
||||
|
||||
Stella_en_1.5B_v5 is trained by [MRL](https://arxiv.org/abs/2205.13147) enabling multiple embedding dimensions.
|
||||
Stella_en_1.5B_v5 is trained by [MRL](https://huggingface.co/papers/2205.13147) enabling multiple embedding dimensions.
|
||||
|
||||
The following reproduces the example in the [model card](https://huggingface.co/dunzhang/stella_en_1.5B_v5) for a retrieval task (s2p). The sample queries and docs are hardcoded in the example.
|
||||
|
||||
|
||||
@ -13,7 +13,7 @@ $ cargo run --example t5 --release -- --model-id "t5-small" --prompt "translate
|
||||
|
||||
Variants such as [flan-t5](https://huggingface.co/google/flan-t5-small), [flan-ul2](https://huggingface.co/google/flan-ul2) (with `--revision "refs/pr/25"`), and [Co-EdIT](https://huggingface.co/grammarly/coedit-large) are also supported.
|
||||
|
||||
## Translation with [MADLAD-400](https://arxiv.org/abs/2309.04662)
|
||||
## Translation with [MADLAD-400](https://huggingface.co/papers/2309.04662)
|
||||
|
||||
MADLAD-400 is a series of multilingual machine translation T5 models trained on 250 billion tokens covering over 450 languages using publicly available data. These models are competitive with significantly larger models.
|
||||
|
||||
|
||||
@ -8,7 +8,7 @@ The candle implementation reproduces the same structure/files for models and
|
||||
pipelines. Useful resources:
|
||||
|
||||
- [Official implementation](https://github.com/dome272/Wuerstchen).
|
||||
- [Arxiv paper](https://arxiv.org/abs/2306.00637).
|
||||
- [Arxiv paper](https://huggingface.co/papers/2306.00637).
|
||||
- Blog post: [Introducing Würstchen: Fast Diffusion for Image Generation](https://huggingface.co/blog/wuerstchen).
|
||||
|
||||
## Getting the weights
|
||||
|
||||
@ -3,6 +3,28 @@
|
||||
#include "cuda_utils.cuh"
|
||||
#include<stdint.h>
|
||||
|
||||
template <typename T>
|
||||
__host__ __device__
|
||||
constexpr T max_value();
|
||||
|
||||
template <>
|
||||
__host__ __device__
|
||||
constexpr int64_t max_value<int64_t>() {
|
||||
return 0x7FFFFFFFFFFFFFFFLL;
|
||||
}
|
||||
|
||||
template <>
|
||||
__host__ __device__
|
||||
constexpr uint32_t max_value<uint32_t>() {
|
||||
return 0xFFFFFFFFu;
|
||||
}
|
||||
|
||||
template <>
|
||||
__host__ __device__
|
||||
constexpr uint8_t max_value<uint8_t>() {
|
||||
return 0xFFu;
|
||||
}
|
||||
|
||||
template<typename T, typename I>
|
||||
__device__ void index_select(
|
||||
const size_t numel,
|
||||
@ -23,11 +45,15 @@ __device__ void index_select(
|
||||
unsigned int left_i = dst_i / (ids_dim_size * right_size);
|
||||
unsigned int id_i = dst_i / right_size % ids_dim_size;
|
||||
unsigned int right_i = dst_i % right_size;
|
||||
if (ids[id_i] == max_value<I>()) {
|
||||
out[dst_i] = static_cast<T>(0);
|
||||
} else {
|
||||
assert(ids[id_i] < src_dim_size);
|
||||
unsigned int src_i = left_i * (src_dim_size * right_size) + ids[id_i] * right_size + right_i;
|
||||
unsigned strided_i = b ? src_i : get_strided_index(src_i, num_dims, dims, strides);
|
||||
out[dst_i] = inp[strided_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#define IS_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \
|
||||
@ -57,12 +83,16 @@ __device__ void gather(
|
||||
) {
|
||||
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
|
||||
size_t post = i % right_size;
|
||||
size_t idx = ids[i];
|
||||
const I idx = ids[i];
|
||||
if (ids[i] == max_value<I>()) {
|
||||
out[i] = static_cast<T>(0);
|
||||
} else {
|
||||
assert(idx < src_dim_size);
|
||||
size_t pre = i / (right_size * ids_dim_size);
|
||||
size_t src_i = (pre * src_dim_size + idx) * right_size + post;
|
||||
out[i] = inp[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#define GATHER_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \
|
||||
@ -93,13 +123,15 @@ __device__ void index_add(
|
||||
const size_t pre = i / right_size;
|
||||
const size_t post = i % right_size;
|
||||
for (unsigned int j = 0; j < ids_dim_size; ++j) {
|
||||
const size_t idx = ids[j];
|
||||
assert(idx < dst_dim_size);
|
||||
const I idx = ids[j];
|
||||
const size_t src_i = (pre * ids_dim_size + j) * right_size + post;
|
||||
if (idx < max_value<I>()) {
|
||||
assert(idx < dst_dim_size);
|
||||
const size_t dst_i = (pre * dst_dim_size + idx) * right_size + post;
|
||||
out[dst_i] += inp[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#define IA_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \
|
||||
@ -130,12 +162,14 @@ __device__ void scatter(
|
||||
const size_t post = i % right_size;
|
||||
for (unsigned int j = 0; j < src_dim_size; ++j) {
|
||||
const size_t src_i = (pre * src_dim_size + j) * right_size + post;
|
||||
const size_t idx = ids[src_i];
|
||||
const I idx = ids[src_i];
|
||||
if (idx < max_value<I>()) {
|
||||
assert(idx < dst_dim_size);
|
||||
const size_t dst_i = (pre * dst_dim_size + idx) * right_size + post;
|
||||
out[dst_i] = inp[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
template<typename T, typename I>
|
||||
@ -154,12 +188,14 @@ __device__ void scatter_add(
|
||||
const size_t post = i % right_size;
|
||||
for (unsigned int j = 0; j < src_dim_size; ++j) {
|
||||
const size_t src_i = (pre * src_dim_size + j) * right_size + post;
|
||||
const size_t idx = ids[src_i];
|
||||
const I idx = ids[src_i];
|
||||
if (idx < max_value<I>()) {
|
||||
assert(idx < dst_dim_size);
|
||||
const size_t dst_i = (pre * dst_dim_size + idx) * right_size + post;
|
||||
out[dst_i] += inp[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
#define S_OP(TYPENAME, INDEX_TYPENAME, FN_NAME) \
|
||||
|
||||
@ -1,6 +1,24 @@
|
||||
#include <metal_stdlib>
|
||||
using namespace metal;
|
||||
|
||||
template <typename T>
|
||||
inline T max_value();
|
||||
|
||||
template <>
|
||||
inline int64_t max_value<int64_t>() {
|
||||
return 0x7FFFFFFFFFFFFFFF;
|
||||
}
|
||||
|
||||
template <>
|
||||
inline uint32_t max_value<uint32_t>() {
|
||||
return 0xFFFFFFFFu;
|
||||
}
|
||||
|
||||
template <>
|
||||
inline uint8_t max_value<uint8_t>() {
|
||||
return 0xFF;
|
||||
}
|
||||
|
||||
METAL_FUNC uint get_strided_index(
|
||||
uint idx,
|
||||
constant size_t &num_dims,
|
||||
@ -35,6 +53,9 @@ METAL_FUNC void index(
|
||||
return;
|
||||
}
|
||||
const size_t id_i = (tid / right_size) % ids_size;
|
||||
if (input_ids[id_i] == max_value<INDEX_TYPENAME>()) {
|
||||
output[tid] = static_cast<TYPENAME>(0);
|
||||
} else {
|
||||
const INDEX_TYPENAME input_i = min(input_ids[id_i], (INDEX_TYPENAME)(src_dim_size - 1));
|
||||
const size_t right_rank_i = tid % right_size;
|
||||
const size_t left_rank_i = tid / right_size / ids_size;
|
||||
@ -46,6 +67,7 @@ METAL_FUNC void index(
|
||||
const size_t src_i = left_rank_i * src_dim_size * right_size + input_i * right_size + right_rank_i;
|
||||
const size_t strided_src_i = contiguous ? src_i : get_strided_index(src_i, src_dim_size, src_dims, src_strides);
|
||||
output[tid] = input[strided_src_i];
|
||||
}
|
||||
}
|
||||
|
||||
# define INDEX_OP(NAME, INDEX_TYPENAME, TYPENAME) \
|
||||
@ -83,10 +105,14 @@ METAL_FUNC void gather(
|
||||
return;
|
||||
}
|
||||
const INDEX_TYPENAME input_i = input_ids[tid];
|
||||
if (input_i == max_value<INDEX_TYPENAME>()) {
|
||||
output[tid] = static_cast<TYPENAME>(0);
|
||||
} else {
|
||||
const size_t right_rank_i = tid % right_size;
|
||||
const size_t left_rank_i = tid / right_size / ids_size;
|
||||
const size_t src_i = (left_rank_i * src_dim_size + input_i) * right_size + right_rank_i;
|
||||
output[tid] = input[src_i];
|
||||
}
|
||||
}
|
||||
|
||||
# define GATHER_OP(NAME, INDEX_TYPENAME, TYPENAME) \
|
||||
@ -124,9 +150,11 @@ METAL_FUNC void scatter(
|
||||
for (unsigned int j = 0; j < src_dim_size; ++j) {
|
||||
const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i;
|
||||
const INDEX_TYPENAME idx = input_ids[src_i];
|
||||
if (idx < max_value<INDEX_TYPENAME>()) {
|
||||
const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i;
|
||||
output[dst_i] = input[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
template<typename TYPENAME, typename INDEX_TYPENAME>
|
||||
@ -149,9 +177,11 @@ METAL_FUNC void scatter_add(
|
||||
for (unsigned int j = 0; j < src_dim_size; ++j) {
|
||||
const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i;
|
||||
const INDEX_TYPENAME idx = input_ids[src_i];
|
||||
if (idx < max_value<INDEX_TYPENAME>()) {
|
||||
const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i;
|
||||
output[dst_i] += input[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# define SCATTER_OP(NAME, INDEX_TYPENAME, TYPENAME) \
|
||||
@ -204,10 +234,12 @@ METAL_FUNC void index_add(
|
||||
const size_t left_rank_i = tid / right_size;
|
||||
for (unsigned int j = 0; j < ids_dim_size; ++j) {
|
||||
const INDEX_TYPENAME idx = input_ids[j];
|
||||
if (idx < max_value<INDEX_TYPENAME>()) {
|
||||
const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i;
|
||||
const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i;
|
||||
output[dst_i] += input[src_i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
# define INDEX_ADD_OP(NAME, INDEX_TYPENAME, TYPENAME) \
|
||||
|
||||
@ -858,7 +858,7 @@ struct finalize_softmax {
|
||||
};
|
||||
|
||||
// Welford's algorithm approach for an online softmax implementation.
|
||||
// Same as the Online normalizer calculation for softmax: https://arxiv.org/pdf/1805.02867.pdf
|
||||
// Same as the Online normalizer calculation for softmax: https://huggingface.co/papers/1805.02867
|
||||
template<typename T, ushort BLOCKSIZE>
|
||||
METAL_FUNC void softmax(
|
||||
constant uint &src_numel,
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
//! Note that this implementation is for inference only, there is no possibility to track the
|
||||
//! running stats.
|
||||
//!
|
||||
//! [`Batch Normalization`]: https://arxiv.org/abs/1502.03167
|
||||
//! [`Batch Normalization`]: https://huggingface.co/papers/1502.03167
|
||||
use candle::{DType, Result, Tensor, Var};
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq)]
|
||||
|
||||
@ -27,7 +27,7 @@
|
||||
//! # Ok(()) }
|
||||
//! ```
|
||||
//!
|
||||
//! [`Layer Normalization`]: https://arxiv.org/abs/1607.06450
|
||||
//! [`Layer Normalization`]: https://huggingface.co/papers/1607.06450
|
||||
use candle::{DType, Module, Result, Tensor, D};
|
||||
|
||||
#[derive(Debug, Clone, Copy, PartialEq)]
|
||||
|
||||
@ -1960,6 +1960,76 @@ fn simple_eval_(
|
||||
let output = input.sign()?;
|
||||
values.insert(node.output[0].clone(), output);
|
||||
}
|
||||
"Resize" => {
|
||||
let input = get(&node.input[0])?;
|
||||
|
||||
if input.rank() != 4 {
|
||||
bail!("Unsupported rank for nearest resize: {}", input.rank());
|
||||
}
|
||||
|
||||
let scales = if node.input.len() > 2 && !node.input[2].is_empty() {
|
||||
Some(get(&node.input[2])?)
|
||||
} else {
|
||||
None
|
||||
};
|
||||
|
||||
let sizes = if node.input.len() > 3 && !node.input[3].is_empty() {
|
||||
Some(get(&node.input[3])?)
|
||||
} else {
|
||||
None
|
||||
};
|
||||
|
||||
let output_dims = match (scales, sizes) {
|
||||
(Some(_), Some(_)) => {
|
||||
bail!("Scales and sizes cannot both be set for Resize operation")
|
||||
}
|
||||
(Some(scales_tensor), None) => {
|
||||
let scale_values = scales_tensor.to_vec1::<f32>()?;
|
||||
input
|
||||
.dims()
|
||||
.iter()
|
||||
.enumerate()
|
||||
.map(|(i, &d)| (d as f32 * scale_values[i]) as usize)
|
||||
.collect::<Vec<_>>()
|
||||
}
|
||||
(None, Some(sizes_tensor)) => sizes_tensor
|
||||
.to_vec1::<i64>()?
|
||||
.iter()
|
||||
.map(|&d| d as usize)
|
||||
.collect::<Vec<_>>(),
|
||||
(None, None) => bail!("Either scales or sizes should be present"),
|
||||
};
|
||||
|
||||
let coordinate_transformation_mode =
|
||||
get_attr_opt::<str>(node, "coordinate_transformation_mode")?
|
||||
.unwrap_or("half_pixel");
|
||||
// Interpolation mode: nearest, linear, or cubic.
|
||||
let mode = get_attr_opt::<str>(node, "mode")?.unwrap_or("nearest");
|
||||
// How to determine the "nearest" pixel in nearest interpolation mode.
|
||||
let nearest_mode =
|
||||
get_attr_opt::<str>(node, "nearest_mode")?.unwrap_or("round_prefer_floor");
|
||||
|
||||
if mode != "nearest" {
|
||||
bail!("Unsupported resize mode: {}", mode);
|
||||
}
|
||||
|
||||
if nearest_mode != "floor" {
|
||||
bail!("Unsupported nearest_mode for resize: {}", nearest_mode);
|
||||
}
|
||||
|
||||
if coordinate_transformation_mode != "asymmetric" {
|
||||
bail!(
|
||||
"Unsupported coordinate_transformation_mode for resize: {}",
|
||||
coordinate_transformation_mode
|
||||
);
|
||||
}
|
||||
|
||||
let h = output_dims[2];
|
||||
let w = output_dims[3];
|
||||
let output = input.upsample_nearest2d(h, w)?;
|
||||
|
||||
values.insert(node.output[0].clone(), output);
|
||||
}
|
||||
op_type => bail!("unsupported op_type {op_type} for op {node:?}"),
|
||||
}
|
||||
}
|
||||
|
||||
@ -512,8 +512,8 @@ message TensorProto {
|
||||
BFLOAT16 = 16;
|
||||
|
||||
// Non-IEEE floating-point format based on papers
|
||||
// FP8 Formats for Deep Learning, https://arxiv.org/abs/2209.05433,
|
||||
// 8-bit Numerical Formats For Deep Neural Networks, https://arxiv.org/pdf/2206.02915.pdf.
|
||||
// FP8 Formats for Deep Learning, https://huggingface.co/papers/2209.05433,
|
||||
// 8-bit Numerical Formats For Deep Neural Networks, https://huggingface.co/papers/2206.02915.
|
||||
// Operators supported FP8 are Cast, CastLike, QuantizeLinear, DequantizeLinear.
|
||||
// The computation usually happens inside a block quantize / dequantize
|
||||
// fused by the runtime.
|
||||
|
||||
@ -9,7 +9,7 @@ import numbers
|
||||
|
||||
class LayerNorm(Module):
|
||||
r"""Applies Layer Normalization over a mini-batch of inputs as described in
|
||||
the paper `Layer Normalization <https://arxiv.org/abs/1607.06450>`
|
||||
the paper `Layer Normalization <https://huggingface.co/papers/1607.06450>`
|
||||
|
||||
math::
|
||||
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Based from the Stanford Hazy Research group.
|
||||
//!
|
||||
//! See "Simple linear attention language models balance the recall-throughput tradeoff", Arora et al. 2024
|
||||
//! - Simple linear attention language models balance the recall-throughput tradeoff. [Arxiv](https://arxiv.org/abs/2402.18668)
|
||||
//! - Simple linear attention language models balance the recall-throughput tradeoff. [Arxiv](https://huggingface.co/papers/2402.18668)
|
||||
//! - [Github Rep](https://github.com/HazyResearch/based)
|
||||
//! - [Blogpost](https://hazyresearch.stanford.edu/blog/2024-03-03-based)
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Based on the BEIT vision-language model.
|
||||
//!
|
||||
//! See "BEIT: BERT Pre-Training of Image Transformers", Bao et al. 2021
|
||||
//! - [Arxiv](https://arxiv.org/abs/2106.08254)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2106.08254)
|
||||
//! - [Github](https://github.com/microsoft/unilm/tree/master/beit)
|
||||
//!
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! Bert is a general large language model that can be used for various language tasks:
|
||||
//! - Compute sentence embeddings for a prompt.
|
||||
//! - Compute similarities between a set of sentences.
|
||||
//! - [Arxiv](https://arxiv.org/abs/1810.04805) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
|
||||
//! - [Arxiv](https://huggingface.co/papers/1810.04805) "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
|
||||
//! - Upstream [Github repo](https://github.com/google-research/bert).
|
||||
//! - See bert in [candle-examples](https://github.com/huggingface/candle/tree/main/candle-examples/) for runnable code
|
||||
//!
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
//! [StarCoder/BigCode](https://huggingface.co/bigcode/starcoderbase-1b) is a LLM
|
||||
//! model specialized to code generation. The initial model was trained on 80
|
||||
//! programming languages. See "StarCoder: A State-of-the-Art LLM for Code", Mukherjee et al. 2023
|
||||
//! - [Arxiv](https://arxiv.org/abs/2305.06161)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2305.06161)
|
||||
//! - [Github](https://github.com/bigcode-project/starcoder)
|
||||
//!
|
||||
//! ## Running some example
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
|
||||
use super::blip_text;
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
//! Implementation of BLIP text encoder/decoder.
|
||||
//!
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
use super::with_tracing::{linear, Embedding, Linear};
|
||||
use candle::{Module, Result, Tensor, D};
|
||||
|
||||
@ -13,9 +13,9 @@ use super::Activation;
|
||||
|
||||
/// Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
|
||||
/// positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
|
||||
/// [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
|
||||
/// [Self-Attention with Relative Position Representations (Shaw et al.)](https://huggingface.co/papers/1803.02155).
|
||||
/// For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
|
||||
/// with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
|
||||
/// with Better Relative Position Embeddings (Huang et al.)](https://huggingface.co/papers/2009.13658).
|
||||
#[derive(Clone, Debug)]
|
||||
pub enum PositionEmbeddingType {
|
||||
Absolute,
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! A Pre-Trained Model For Code Generation with Multilingual Evaluations on HumanEval-X"
|
||||
//!
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2303.17568)
|
||||
//! - 📝 [Arxiv](https://huggingface.co/papers/2303.17568)
|
||||
//! - 💻 [Github](https://github.com/THUDM/CodeGeeX)
|
||||
//!
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! See "Patches Are All You Need?" by Trockman et al. 2022
|
||||
//!
|
||||
//! - 📝 [Arxiv](https://arxiv.org/abs/2201.09792)
|
||||
//! - 📝 [Arxiv](https://huggingface.co/papers/2201.09792)
|
||||
//! - 💻 [Github](https://github.com/locuslab/convmixer)
|
||||
//!
|
||||
use candle::Result;
|
||||
|
||||
@ -8,8 +8,8 @@
|
||||
//! - 💻 [ConvNeXt](https://github.com/facebookresearch/ConvNeXt/)
|
||||
//! - 💻 [ConvNeXt-V2](https://github.com/facebookresearch/ConvNeXt-V2/)
|
||||
//! - 💻 [timm](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/convnext.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.03545) A ConvNet for the 2020s
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2301.00808) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.03545) A ConvNet for the 2020s
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2301.00808) ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
|
||||
//!
|
||||
|
||||
use candle::shape::ShapeWithOneHole;
|
||||
|
||||
@ -869,8 +869,8 @@ impl Moe {
|
||||
}
|
||||
|
||||
enum MoeOrMlp {
|
||||
Moe(Moe),
|
||||
Mlp(Mlp),
|
||||
Moe(Box<Moe>),
|
||||
Mlp(Box<Mlp>),
|
||||
}
|
||||
|
||||
impl MoeOrMlp {
|
||||
@ -908,14 +908,17 @@ impl DecoderLayer {
|
||||
&& layer_idx >= cfg.first_k_dense_replace
|
||||
&& layer_idx % cfg.moe_layer_freq == 0
|
||||
{
|
||||
MoeOrMlp::Moe(Moe::new(
|
||||
MoeOrMlp::Moe(
|
||||
Moe::new(
|
||||
cfg,
|
||||
vb.pp("mlp"),
|
||||
cfg.n_shared_experts,
|
||||
cfg.n_routed_experts.unwrap(),
|
||||
)?)
|
||||
)?
|
||||
.into(),
|
||||
)
|
||||
} else {
|
||||
MoeOrMlp::Mlp(Mlp::new(cfg, vb.pp("mlp"), None, None)?)
|
||||
MoeOrMlp::Mlp(Mlp::new(cfg, vb.pp("mlp"), None, None)?.into())
|
||||
};
|
||||
|
||||
Ok(Self {
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! original architecture. This implementation is specifically trained for plant species
|
||||
//! classification on the PlantCLEF2024 dataset with 7,806 classes.
|
||||
//!
|
||||
//! - [Paper](https://arxiv.org/abs/2309.16588). DINOv2: Learning Robust Visual Features without Supervision
|
||||
//! - [Paper](https://huggingface.co/papers/2309.16588). DINOv2: Learning Robust Visual Features without Supervision
|
||||
//! - [GH Repo](https://github.com/facebookresearch/dinov2)
|
||||
//!
|
||||
//! # Example
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Implementation of DistilBert, a distilled version of BERT.
|
||||
//!
|
||||
//! See:
|
||||
//! - ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://arxiv.org/abs/1910.01108)
|
||||
//! - ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://huggingface.co/papers/1910.01108)
|
||||
//!
|
||||
use super::with_tracing::{layer_norm, linear, LayerNorm, Linear};
|
||||
use candle::{DType, Device, Result, Tensor};
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Implementation of EfficientBert, an efficient variant of BERT for computer vision tasks.
|
||||
//!
|
||||
//! See:
|
||||
//! - ["EfficientBERT: Progressively Searching Multilayer Perceptron Architectures for BERT"](https://arxiv.org/abs/2201.00462)
|
||||
//! - ["EfficientBERT: Progressively Searching Multilayer Perceptron Architectures for BERT"](https://huggingface.co/papers/2201.00462)
|
||||
//!
|
||||
use candle::{Context, Result, Tensor, D};
|
||||
use candle_nn as nn;
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
//! to achieve strong performance while maintaining low memory usage.
|
||||
//!
|
||||
//! The model was originally described in the paper:
|
||||
//! ["EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention"](https://arxiv.org/abs/2305.07027)
|
||||
//! ["EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention"](https://huggingface.co/papers/2305.07027)
|
||||
//!
|
||||
//! This implementation is based on the reference implementation from
|
||||
//! [pytorch-image-models](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/efficientvit_msra.py).
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! EnCodec neural audio codec based on the Encodec implementation.
|
||||
//!
|
||||
//! See ["High Fidelity Neural Audio Compression"](https://arxiv.org/abs/2210.13438)
|
||||
//! See ["High Fidelity Neural Audio Compression"](https://huggingface.co/papers/2210.13438)
|
||||
//!
|
||||
//! Based on implementation from [huggingface/transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/encodec/modeling_encodec.py)
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! The model returns the probability for an image to belong to each of the 1000
|
||||
//! ImageNet categories.
|
||||
//!
|
||||
//! - [Paper](https://arxiv.org/abs/2303.11331). EVA-02: A Visual Representation for Neon Genesis
|
||||
//! - [Paper](https://huggingface.co/papers/2303.11331). EVA-02: A Visual Representation for Neon Genesis
|
||||
//! - [Code](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/eva2.py)
|
||||
//!
|
||||
//! # Example
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! # FastViT inference implementation based on timm
|
||||
//!
|
||||
//! ## Description
|
||||
//! See ["FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"](https://arxiv.org/pdf/2303.14189)
|
||||
//! See ["FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"](https://huggingface.co/papers/2303.14189)
|
||||
//!
|
||||
//! Implementation based on [timm model](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/fastvit.py)
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//!
|
||||
//! - 💻 [Hiera](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/hiera.py)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2306.00989). Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2306.00989). Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
|
||||
|
||||
use candle::{Result, D};
|
||||
use candle_nn::{conv2d, layer_norm, linear, ops::softmax, Conv2dConfig, Func, VarBuilder};
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA: Open and Efficient Foundation Language Models"](https://arxiv.org/abs/2302.13971)
|
||||
//! See ["LLaMA: Open and Efficient Foundation Language Models"](https://huggingface.co/papers/2302.13971)
|
||||
//!
|
||||
//! Implementation based on Hugging Face's [transformers](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py)
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama2 inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://huggingface.co/papers/2307.09288)
|
||||
//!
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/lmz/candle-llama2)
|
||||
//! - 💻 llama2.c [GH Link](https://github.com/karpathy/llama2.c)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Llama2 inference implementation.
|
||||
//!
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://arxiv.org/abs/2307.09288)
|
||||
//! See ["LLaMA 2: Open Foundation and Fine-Tuned Chat Models"](https://huggingface.co/papers/2307.09288)
|
||||
//!
|
||||
//! Based on the [llama2.c](https://github.com/karpathy/llama2.c) implementation
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//! language model (Llama) for multimodal capabilities. The architecture implements the training-free projection technique.
|
||||
//!
|
||||
//! - 💻[GH Link](https://github.com/haotian-liu/LLaVA/tree/main)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2304.08485)/ Visual Instruction Tuning
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2304.08485)/ Visual Instruction Tuning
|
||||
//!
|
||||
|
||||
pub mod config;
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
//! Mamba inference implementation.
|
||||
//!
|
||||
//! See ["Mamba: Linear-Time Sequence Modeling with Selective State Spaces"](https://arxiv.org/abs/2312.00752)
|
||||
//! See ["Mamba: Linear-Time Sequence Modeling with Selective State Spaces"](https://huggingface.co/papers/2312.00752)
|
||||
//!
|
||||
//! Based on reference implementation from the AlbertMamba project
|
||||
//! A fast implementation of mamba for inference only.
|
||||
@ -122,7 +122,7 @@ impl MambaBlock {
|
||||
let proj_for_conv = candle_nn::ops::silu(&proj_for_conv)?;
|
||||
// SSM + Selection, we're doing inference here so only need the last step of
|
||||
// the sequence.
|
||||
// Algorithm 3.2 on page 6, https://arxiv.org/pdf/2312.00752.pdf
|
||||
// Algorithm 3.2 on page 6, https://huggingface.co/papers/2312.00752
|
||||
|
||||
let x_proj = self.x_proj.forward(&proj_for_conv)?;
|
||||
let delta = x_proj.narrow(D::Minus1, 0, self.dt_rank)?.contiguous()?;
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
//! MixFormer (Microsoft's Phi Architecture)
|
||||
//!
|
||||
//! See "Textbooks Are All You Need II: phi-1.5 technical report", Lin et al. 2023
|
||||
//! - [Arxiv](https://arxiv.org/abs/2309.05463)
|
||||
//! - [Arxiv](https://huggingface.co/papers/2309.05463)
|
||||
//! - [Github](https://huggingface.co/microsoft/phi-1_5)
|
||||
//!
|
||||
|
||||
use crate::models::with_tracing::{linear, Embedding as E, Linear};
|
||||
/// MixFormer model.
|
||||
/// https://huggingface.co/microsoft/phi-1_5
|
||||
/// https://arxiv.org/abs/2309.05463
|
||||
/// https://huggingface.co/papers/2309.05463
|
||||
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
|
||||
use candle_nn::{Activation, VarBuilder};
|
||||
use serde::Deserialize;
|
||||
|
||||
@ -3,14 +3,14 @@
|
||||
//! Mix of Multi-scale Dilated and Traditional Convolutions (MMDiT) is an architecture
|
||||
//! introduced for Stable Diffusion 3, with the MMDiT-X variant used in Stable Diffusion 3.5.
|
||||
//!
|
||||
//! - 📝 [Research Paper](https://arxiv.org/abs/2403.03206)
|
||||
//! - 📝 [Research Paper](https://huggingface.co/papers/2403.03206)
|
||||
//! - 💻 ComfyUI [reference implementation](https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py)
|
||||
//! - 💻 Stability-AI [MMDiT-X implementation](https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py)
|
||||
|
||||
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
|
||||
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
|
||||
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2201.12086)
|
||||
//!
|
||||
|
||||
pub mod blocks;
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
// Implement the MMDiT model originally introduced for Stable Diffusion 3 (https://arxiv.org/abs/2403.03206),
|
||||
// Implement the MMDiT model originally introduced for Stable Diffusion 3 (https://huggingface.co/papers/2403.03206),
|
||||
// as well as the MMDiT-X variant introduced for Stable Diffusion 3.5-medium (https://huggingface.co/stabilityai/stable-diffusion-3.5-medium)
|
||||
// This follows the implementation of the MMDiT model in the ComfyUI repository.
|
||||
// https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py#L1
|
||||
|
||||
@ -6,12 +6,12 @@
|
||||
//! - Projection layers to align the feature spaces
|
||||
//!
|
||||
//! See model details at:
|
||||
//! - [FastViT](https://arxiv.org/abs/2303.14189)
|
||||
//! - [FastViT](https://huggingface.co/papers/2303.14189)
|
||||
//! - [OpenCLIP](https://github.com/mlfoundations/open_clip)
|
||||
//!
|
||||
//! References:
|
||||
//! - [MobileVLM](https://huggingface.co/mobileVLM)
|
||||
//! - [MetaCLIP](https://arxiv.org/abs/2309.16671)
|
||||
//! - [MetaCLIP](https://huggingface.co/papers/2309.16671)
|
||||
//!
|
||||
|
||||
use super::fastvit;
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//!
|
||||
//! ## Paper
|
||||
//!
|
||||
//! ["MobileNetV4 - Universal Models for the Mobile Ecosystem"](https://arxiv.org/abs/2404.10518)
|
||||
//! ["MobileNetV4 - Universal Models for the Mobile Ecosystem"](https://huggingface.co/papers/2404.10518)
|
||||
//!
|
||||
//! ## References
|
||||
//!
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! MobileOne inference implementation based on timm and candle-repvgg
|
||||
//!
|
||||
//! See ["MobileOne: An Improved One millisecond Mobile Backbone"](https://arxiv.org/abs/2206.04040)
|
||||
//! See ["MobileOne: An Improved One millisecond Mobile Backbone"](https://huggingface.co/papers/2206.04040)
|
||||
|
||||
use candle::{DType, Result, Tensor, D};
|
||||
use candle_nn::{
|
||||
|
||||
@ -70,6 +70,7 @@ pub mod moondream;
|
||||
pub mod mpt;
|
||||
pub mod nvembed_v2;
|
||||
pub mod olmo;
|
||||
pub mod olmo2;
|
||||
pub mod openclip;
|
||||
pub mod paligemma;
|
||||
pub mod parler_tts;
|
||||
@ -90,6 +91,7 @@ pub mod quantized_mpt;
|
||||
pub mod quantized_phi;
|
||||
pub mod quantized_phi3;
|
||||
pub mod quantized_qwen2;
|
||||
pub mod quantized_qwen3;
|
||||
pub mod quantized_recurrent_gemma;
|
||||
pub mod quantized_rwkv_v5;
|
||||
pub mod quantized_rwkv_v6;
|
||||
@ -97,6 +99,7 @@ pub mod quantized_stable_lm;
|
||||
pub mod quantized_t5;
|
||||
pub mod qwen2;
|
||||
pub mod qwen2_moe;
|
||||
pub mod qwen3;
|
||||
pub mod recurrent_gemma;
|
||||
pub mod repvgg;
|
||||
pub mod resnet;
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! ModernBERT
|
||||
//!
|
||||
//! ModernBERT is a modernized bidirectional encoder-only Transformer model.
|
||||
//! - [Arxiv](https://arxiv.org/abs/2412.13663) "Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference"
|
||||
//! - [Arxiv](https://huggingface.co/papers/2412.13663) "Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference"
|
||||
//! - Upstream [Github repo](https://github.com/AnswerDotAI/ModernBERT).
|
||||
//! - See modernbert in [candle-examples](https://github.com/huggingface/candle/tree/main/candle-examples/) for runnable code
|
||||
//!
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
//!
|
||||
//! NV-Embed-v2 is a text embedding model that combines a Mistral decoder with a latent attention mechanism to produce high-quality text embeddings.
|
||||
//!
|
||||
//! This implementation is based on the [paper](https://arxiv.org/pdf/2405.17428) and [weights](https://huggingface.co/nvidia/NV-Embed-v2)
|
||||
//! This implementation is based on the [paper](https://huggingface.co/papers/2405.17428) and [weights](https://huggingface.co/nvidia/NV-Embed-v2)
|
||||
//!
|
||||
//! # Query-Passage Retrieval Example
|
||||
//! ```bash
|
||||
|
||||
348
candle-transformers/src/models/olmo2.rs
Normal file
348
candle-transformers/src/models/olmo2.rs
Normal file
@ -0,0 +1,348 @@
|
||||
//! OLMo 2 (Open Language Model) implementation
|
||||
//!
|
||||
//! See OLMo 2 model details at:
|
||||
//! - [Hugging Face Collection](https://huggingface.co/collections/allenai/olmo-2-674117b93ab84e98afc72edc)
|
||||
//! - [OLMo 2 Paper](https://huggingface.co/papers/2501.00656)
|
||||
//!
|
||||
//!
|
||||
use candle::{DType, Device, Module, Result, Tensor, D};
|
||||
use candle_nn::{linear_b, linear_no_bias, rms_norm, Activation, Linear, RmsNorm, VarBuilder};
|
||||
use std::sync::Arc;
|
||||
|
||||
#[derive(Debug, Clone, serde::Deserialize)]
|
||||
pub struct Config {
|
||||
pub vocab_size: usize,
|
||||
pub hidden_size: usize,
|
||||
pub intermediate_size: usize,
|
||||
pub attention_bias: bool,
|
||||
pub num_hidden_layers: usize,
|
||||
pub num_attention_heads: usize,
|
||||
pub num_key_value_heads: usize,
|
||||
pub rms_norm_eps: f64,
|
||||
pub hidden_act: candle_nn::Activation,
|
||||
pub max_position_embeddings: usize,
|
||||
pub rope_theta: f64,
|
||||
pub tie_word_embeddings: bool,
|
||||
pub clip_qkv: Option<f64>,
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct RotaryEmbedding {
|
||||
sin: Tensor,
|
||||
cos: Tensor,
|
||||
}
|
||||
|
||||
impl RotaryEmbedding {
|
||||
fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
|
||||
let dim = cfg.hidden_size / cfg.num_attention_heads;
|
||||
let max_seq_len = cfg.max_position_embeddings;
|
||||
let inv_freq: Vec<_> = (0..dim)
|
||||
.step_by(2)
|
||||
.map(|i| 1f32 / cfg.rope_theta.powf(i as f64 / dim as f64) as f32)
|
||||
.collect();
|
||||
let inv_freq_len = inv_freq.len();
|
||||
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
|
||||
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
|
||||
.to_dtype(dtype)?
|
||||
.reshape((max_seq_len, 1))?;
|
||||
let freqs = t.matmul(&inv_freq)?;
|
||||
Ok(Self {
|
||||
sin: freqs.sin()?,
|
||||
cos: freqs.cos()?,
|
||||
})
|
||||
}
|
||||
|
||||
fn apply_rotary_emb_qkv(
|
||||
&self,
|
||||
q: &Tensor,
|
||||
k: &Tensor,
|
||||
seqlen_offset: usize,
|
||||
) -> Result<(Tensor, Tensor)> {
|
||||
let (_b_sz, _h, seq_len, _n_embd) = q.dims4()?;
|
||||
let cos = self.cos.narrow(0, seqlen_offset, seq_len)?;
|
||||
let sin = self.sin.narrow(0, seqlen_offset, seq_len)?;
|
||||
let q_embed = candle_nn::rotary_emb::rope(&q.contiguous()?, &cos, &sin)?;
|
||||
let k_embed = candle_nn::rotary_emb::rope(&k.contiguous()?, &cos, &sin)?;
|
||||
Ok((q_embed, k_embed))
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
#[allow(clippy::upper_case_acronyms)]
|
||||
struct MLP {
|
||||
gate_proj: Linear,
|
||||
up_proj: Linear,
|
||||
down_proj: Linear,
|
||||
act_fn: Activation,
|
||||
}
|
||||
|
||||
impl MLP {
|
||||
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let hidden_sz = cfg.hidden_size;
|
||||
let intermediate_sz = cfg.intermediate_size;
|
||||
let gate_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("gate_proj"))?;
|
||||
let up_proj = linear_no_bias(hidden_sz, intermediate_sz, vb.pp("up_proj"))?;
|
||||
let down_proj = linear_no_bias(intermediate_sz, hidden_sz, vb.pp("down_proj"))?;
|
||||
Ok(Self {
|
||||
gate_proj,
|
||||
up_proj,
|
||||
down_proj,
|
||||
act_fn: cfg.hidden_act,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
impl Module for MLP {
|
||||
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
|
||||
let lhs = xs.apply(&self.gate_proj)?.apply(&self.act_fn)?;
|
||||
let rhs = xs.apply(&self.up_proj)?;
|
||||
(lhs * rhs)?.apply(&self.down_proj)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct Attention {
|
||||
q_proj: Linear,
|
||||
k_proj: Linear,
|
||||
v_proj: Linear,
|
||||
o_proj: Linear,
|
||||
q_norm: RmsNorm,
|
||||
k_norm: RmsNorm,
|
||||
num_heads: usize,
|
||||
num_kv_heads: usize,
|
||||
num_kv_groups: usize,
|
||||
head_dim: usize,
|
||||
hidden_size: usize,
|
||||
rotary_emb: Arc<RotaryEmbedding>,
|
||||
kv_cache: Option<(Tensor, Tensor)>,
|
||||
}
|
||||
|
||||
impl Attention {
|
||||
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let hidden_sz = cfg.hidden_size;
|
||||
let num_heads = cfg.num_attention_heads;
|
||||
let num_kv_heads = cfg.num_key_value_heads;
|
||||
let num_kv_groups = num_heads / num_kv_heads;
|
||||
let head_dim = hidden_sz / num_heads;
|
||||
let b = cfg.attention_bias;
|
||||
let q_proj = linear_b(hidden_sz, num_heads * head_dim, b, vb.pp("q_proj"))?;
|
||||
let k_proj = linear_b(hidden_sz, num_kv_heads * head_dim, b, vb.pp("k_proj"))?;
|
||||
let v_proj = linear_b(hidden_sz, num_kv_heads * head_dim, b, vb.pp("v_proj"))?;
|
||||
let o_proj = linear_b(num_heads * head_dim, hidden_sz, b, vb.pp("o_proj"))?;
|
||||
let q_norm = rms_norm(hidden_sz, cfg.rms_norm_eps, vb.pp("q_norm"))?;
|
||||
let k_norm = rms_norm(num_kv_heads * head_dim, cfg.rms_norm_eps, vb.pp("k_norm"))?;
|
||||
Ok(Self {
|
||||
q_proj,
|
||||
k_proj,
|
||||
v_proj,
|
||||
o_proj,
|
||||
q_norm,
|
||||
k_norm,
|
||||
num_heads,
|
||||
num_kv_heads,
|
||||
num_kv_groups,
|
||||
head_dim,
|
||||
hidden_size: hidden_sz,
|
||||
rotary_emb,
|
||||
kv_cache: None,
|
||||
})
|
||||
}
|
||||
|
||||
fn forward(
|
||||
&mut self,
|
||||
xs: &Tensor,
|
||||
attention_mask: Option<&Tensor>,
|
||||
seqlen_offset: usize,
|
||||
) -> Result<Tensor> {
|
||||
let (b_sz, q_len, _) = xs.dims3()?;
|
||||
|
||||
let query_states = self.q_proj.forward(xs)?;
|
||||
let key_states = self.k_proj.forward(xs)?;
|
||||
let value_states = self.v_proj.forward(xs)?;
|
||||
|
||||
let query_states = self.q_norm.forward(&query_states)?;
|
||||
let key_states = self.k_norm.forward(&key_states)?;
|
||||
|
||||
let query_states = query_states
|
||||
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let key_states = key_states
|
||||
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let value_states = value_states
|
||||
.reshape((b_sz, q_len, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
|
||||
let (query_states, key_states) =
|
||||
self.rotary_emb
|
||||
.apply_rotary_emb_qkv(&query_states, &key_states, seqlen_offset)?;
|
||||
|
||||
let (key_states, value_states) = match &self.kv_cache {
|
||||
None => (key_states, value_states),
|
||||
Some((prev_k, prev_v)) => {
|
||||
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
|
||||
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
|
||||
(key_states, value_states)
|
||||
}
|
||||
};
|
||||
self.kv_cache = Some((key_states.clone(), value_states.clone()));
|
||||
|
||||
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?.contiguous()?;
|
||||
let value_states =
|
||||
crate::utils::repeat_kv(value_states, self.num_kv_groups)?.contiguous()?;
|
||||
|
||||
let attn_output = {
|
||||
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
|
||||
let attn_weights = (query_states.matmul(&key_states.transpose(2, 3)?)? * scale)?;
|
||||
|
||||
let attn_weights = match attention_mask {
|
||||
None => attn_weights,
|
||||
Some(mask) => attn_weights.broadcast_add(mask)?,
|
||||
};
|
||||
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
|
||||
attn_weights.matmul(&value_states)?
|
||||
};
|
||||
attn_output
|
||||
.transpose(1, 2)?
|
||||
.reshape((b_sz, q_len, self.hidden_size))?
|
||||
.apply(&self.o_proj)
|
||||
}
|
||||
|
||||
fn clear_kv_cache(&mut self) {
|
||||
self.kv_cache = None
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct DecoderLayer {
|
||||
self_attn: Attention,
|
||||
mlp: MLP,
|
||||
post_attention_layernorm: RmsNorm,
|
||||
post_feedforward_layernorm: RmsNorm,
|
||||
}
|
||||
|
||||
impl DecoderLayer {
|
||||
fn new(rotary_emb: Arc<RotaryEmbedding>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let self_attn = Attention::new(rotary_emb, cfg, vb.pp("self_attn"))?;
|
||||
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
|
||||
let post_feedforward_layernorm = rms_norm(
|
||||
cfg.hidden_size,
|
||||
cfg.rms_norm_eps,
|
||||
vb.pp("post_feedforward_layernorm"),
|
||||
)?;
|
||||
let post_attention_layernorm = rms_norm(
|
||||
cfg.hidden_size,
|
||||
cfg.rms_norm_eps,
|
||||
vb.pp("post_attention_layernorm"),
|
||||
)?;
|
||||
Ok(Self {
|
||||
self_attn,
|
||||
mlp,
|
||||
post_attention_layernorm,
|
||||
post_feedforward_layernorm,
|
||||
})
|
||||
}
|
||||
|
||||
fn forward(
|
||||
&mut self,
|
||||
xs: &Tensor,
|
||||
attention_mask: Option<&Tensor>,
|
||||
seqlen_offset: usize,
|
||||
) -> Result<Tensor> {
|
||||
let residual = xs;
|
||||
let xs = self.self_attn.forward(xs, attention_mask, seqlen_offset)?;
|
||||
let xs = self.post_attention_layernorm.forward(&xs)?;
|
||||
let xs = (xs + residual)?;
|
||||
let residual = &xs;
|
||||
let xs = self.mlp.forward(&xs)?;
|
||||
let xs = self.post_feedforward_layernorm.forward(&xs)?;
|
||||
residual + xs
|
||||
}
|
||||
|
||||
fn clear_kv_cache(&mut self) {
|
||||
self.self_attn.clear_kv_cache()
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub struct Model {
|
||||
embed_tokens: candle_nn::Embedding,
|
||||
layers: Vec<DecoderLayer>,
|
||||
norm: RmsNorm,
|
||||
lm_head: Linear,
|
||||
device: Device,
|
||||
dtype: DType,
|
||||
}
|
||||
|
||||
impl Model {
|
||||
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let vb_m = vb.pp("model");
|
||||
let embed_tokens =
|
||||
candle_nn::embedding(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
|
||||
let rotary_emb = Arc::new(RotaryEmbedding::new(vb.dtype(), cfg, vb_m.device())?);
|
||||
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
|
||||
let vb_l = vb_m.pp("layers");
|
||||
for layer_idx in 0..cfg.num_hidden_layers {
|
||||
let layer = DecoderLayer::new(rotary_emb.clone(), cfg, vb_l.pp(layer_idx))?;
|
||||
layers.push(layer)
|
||||
}
|
||||
let norm = rms_norm(cfg.hidden_size, cfg.rms_norm_eps, vb_m.pp("norm"))?;
|
||||
let lm_head = if cfg.tie_word_embeddings {
|
||||
Linear::new(embed_tokens.embeddings().clone(), None)
|
||||
} else {
|
||||
linear_no_bias(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?
|
||||
};
|
||||
Ok(Self {
|
||||
embed_tokens,
|
||||
layers,
|
||||
norm,
|
||||
lm_head,
|
||||
device: vb.device().clone(),
|
||||
dtype: vb.dtype(),
|
||||
})
|
||||
}
|
||||
|
||||
fn prepare_decoder_attention_mask(
|
||||
&self,
|
||||
b_size: usize,
|
||||
tgt_len: usize,
|
||||
seqlen_offset: usize,
|
||||
) -> Result<Tensor> {
|
||||
// Sliding window mask?
|
||||
let mask: Vec<_> = (0..tgt_len)
|
||||
.flat_map(|i| (0..tgt_len).map(move |j| if i < j { f32::NEG_INFINITY } else { 0. }))
|
||||
.collect();
|
||||
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
|
||||
let mask = if seqlen_offset > 0 {
|
||||
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), self.dtype, &self.device)?;
|
||||
Tensor::cat(&[&mask0, &mask], D::Minus1)?
|
||||
} else {
|
||||
mask
|
||||
};
|
||||
mask.expand((b_size, 1, tgt_len, tgt_len + seqlen_offset))?
|
||||
.to_dtype(self.dtype)
|
||||
}
|
||||
|
||||
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
|
||||
let (b_size, seq_len) = input_ids.dims2()?;
|
||||
let attention_mask = if seq_len <= 1 {
|
||||
None
|
||||
} else {
|
||||
let mask = self.prepare_decoder_attention_mask(b_size, seq_len, seqlen_offset)?;
|
||||
Some(mask)
|
||||
};
|
||||
let mut xs = self.embed_tokens.forward(input_ids)?;
|
||||
for layer in self.layers.iter_mut() {
|
||||
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
|
||||
}
|
||||
xs.narrow(1, seq_len - 1, 1)?
|
||||
.apply(&self.norm)?
|
||||
.apply(&self.lm_head)
|
||||
}
|
||||
|
||||
pub fn clear_kv_cache(&mut self) {
|
||||
for layer in self.layers.iter_mut() {
|
||||
layer.clear_kv_cache()
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -4,7 +4,7 @@
|
||||
//! pairs of images with related texts.
|
||||
//!
|
||||
//! - 💻 [GH Link](https://github.com/mlfoundations/open_clip)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2212.07143)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2212.07143)
|
||||
//!
|
||||
//! ## Overview
|
||||
//!
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
//! Multimodal multi-purpose model combining Gemma-based language model with SigLIP image understanding
|
||||
//!
|
||||
//! See PaLiGemma details at:
|
||||
//! - [Paper](https://arxiv.org/abs/2402.05257)
|
||||
//! - [Paper](https://huggingface.co/papers/2402.05257)
|
||||
//! - [Google Blog Post](https://blog.research.google/2024/02/paligemma-scaling-language-image.html)
|
||||
//!
|
||||
//! The model is a multimodal combination of:
|
||||
@ -11,7 +11,7 @@
|
||||
//!
|
||||
//! References:
|
||||
//! - [HuggingFace Implementation](https://huggingface.co/google/paligemma-3b)
|
||||
//! - [Paper: PaLI-3 and Beyond: Scaling Language-Image Learning](https://arxiv.org/abs/2402.05257)
|
||||
//! - [Paper: PaLI-3 and Beyond: Scaling Language-Image Learning](https://huggingface.co/papers/2402.05257)
|
||||
//!
|
||||
|
||||
use crate::models::{gemma, siglip};
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [BLIP Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - [BLIP Paper](https://huggingface.co/papers/2201.12086)
|
||||
//! - [Hugging Face Implementation](https://huggingface.co/docs/transformers/model_doc/blip)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Quantized linear transformations
|
||||
//!
|
||||
//! References:
|
||||
//! - [BLIP Paper](https://arxiv.org/abs/2201.12086)
|
||||
//! - [BLIP Paper](https://huggingface.co/papers/2201.12086)
|
||||
//! - [Hugging Face Implementation](https://huggingface.co/docs/transformers/model_doc/blip)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Configurable model sizes and parameter counts
|
||||
//!
|
||||
//! - 💻 [GH Link](https://github.com/facebookresearch/llama)
|
||||
//! - 📝 [Paper](https://arxiv.org/abs/2302.13971)
|
||||
//! - 📝 [Paper](https://huggingface.co/papers/2302.13971)
|
||||
//!
|
||||
//! 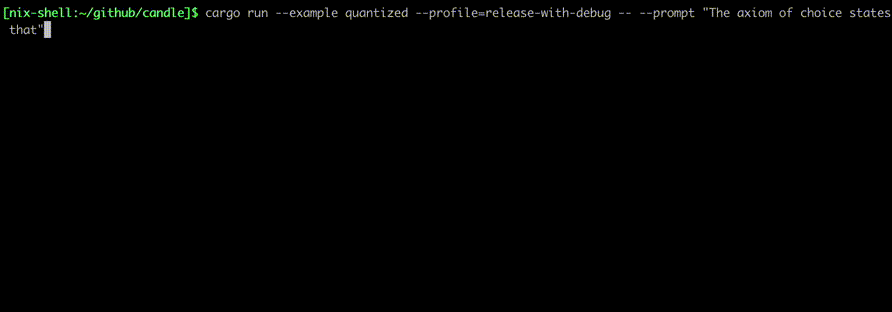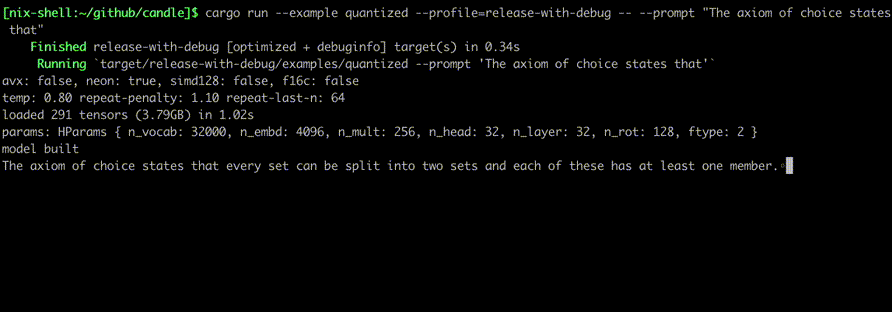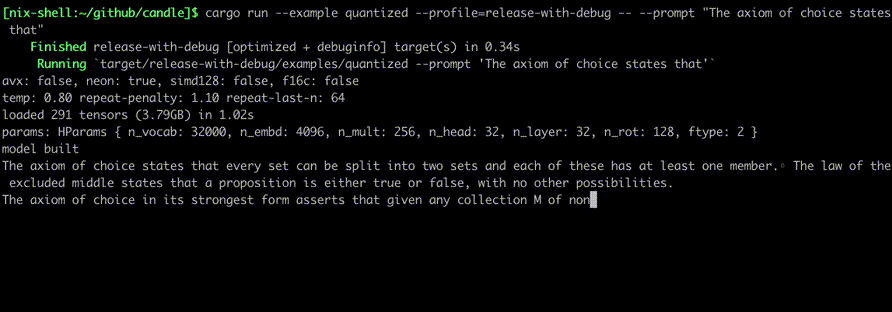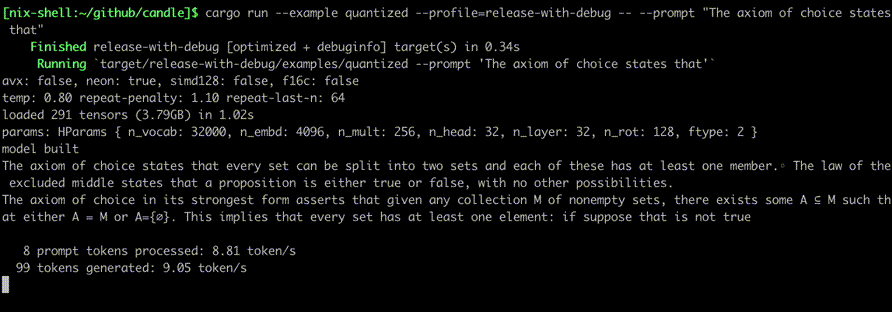
|
||||
//!
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - 8-bit quantization of weights
|
||||
//!
|
||||
//! References:
|
||||
//! - [LLaMA2 Paper](https://arxiv.org/abs/2307.09288)
|
||||
//! - [LLaMA2 Paper](https://huggingface.co/papers/2307.09288)
|
||||
//! - [LLaMA2 Technical Report](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Mistral Paper](https://arxiv.org/abs/2310.06825)
|
||||
//! - [Mistral Paper](https://huggingface.co/papers/2310.06825)
|
||||
//! - [Model Card](https://huggingface.co/mistralai/Mistral-7B-v0.1)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Phi2 Paper](https://arxiv.org/abs/2309.05463)
|
||||
//! - [Phi2 Paper](https://huggingface.co/papers/2309.05463)
|
||||
//! - [Model Card](https://huggingface.co/microsoft/phi-2)
|
||||
//!
|
||||
|
||||
|
||||
429
candle-transformers/src/models/quantized_qwen3.rs
Normal file
429
candle-transformers/src/models/quantized_qwen3.rs
Normal file
@ -0,0 +1,429 @@
|
||||
//! Qwen3 implementation with quantization support.
|
||||
//!
|
||||
//! Based on the Qwen3 architecture and implemented with quantized weights
|
||||
//! for reduced memory usage and faster inference on compatible hardware.
|
||||
//!
|
||||
//! References:
|
||||
//! - [Qwen3 Models](https://huggingface.co/Qwen/Qwen3-0.6B) (architecture based on official implementations)
|
||||
//!
|
||||
use super::with_tracing::QMatMul;
|
||||
use crate::{quantized_nn::RmsNorm, utils::repeat_kv};
|
||||
use candle::quantized::{gguf_file, QTensor};
|
||||
use candle::{DType, Device, Result, Tensor};
|
||||
use candle_nn::{kv_cache::KvCache, Activation, Embedding, Module};
|
||||
use std::io::{Read, Seek};
|
||||
use std::sync::Arc;
|
||||
|
||||
struct Gguf<R: Read + Seek> {
|
||||
ct: gguf_file::Content,
|
||||
reader: R,
|
||||
device: Device,
|
||||
}
|
||||
|
||||
impl<R: Read + Seek> Gguf<R> {
|
||||
fn new(ct: gguf_file::Content, reader: R, device: Device) -> Self {
|
||||
Self { ct, reader, device }
|
||||
}
|
||||
|
||||
fn qmatmul(&mut self, name: &str) -> Result<QMatMul> {
|
||||
let ws = self.ct.tensor(&mut self.reader, name, &self.device)?;
|
||||
QMatMul::from_weights(ws.into())
|
||||
}
|
||||
|
||||
fn rms_norm(&mut self, name: &str, eps: f64) -> Result<RmsNorm> {
|
||||
let ws = self.ct.tensor(&mut self.reader, name, &self.device)?;
|
||||
RmsNorm::from_qtensor(ws, eps)
|
||||
}
|
||||
|
||||
fn metadata(&self) -> &std::collections::HashMap<String, gguf_file::Value> {
|
||||
&self.ct.metadata
|
||||
}
|
||||
|
||||
fn tensor(&mut self, name: &str) -> Result<QTensor> {
|
||||
self.ct.tensor(&mut self.reader, name, &self.device)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct MlpWeights {
|
||||
gate_proj: QMatMul,
|
||||
up_proj: QMatMul,
|
||||
down_proj: QMatMul,
|
||||
act_fn: Activation,
|
||||
span: tracing::Span,
|
||||
}
|
||||
|
||||
impl MlpWeights {
|
||||
fn new<R: Read + Seek>(gg: &mut Gguf<R>, prefix: &str) -> Result<Self> {
|
||||
let gate_proj = gg.qmatmul(&format!("{prefix}.ffn_gate.weight"))?;
|
||||
let up_proj = gg.qmatmul(&format!("{prefix}.ffn_up.weight"))?;
|
||||
let down_proj = gg.qmatmul(&format!("{prefix}.ffn_down.weight"))?;
|
||||
let act_fn = Activation::Silu;
|
||||
let span = tracing::span!(tracing::Level::TRACE, "mlp");
|
||||
Ok(Self {
|
||||
gate_proj,
|
||||
up_proj,
|
||||
down_proj,
|
||||
act_fn,
|
||||
span,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
impl Module for MlpWeights {
|
||||
fn forward(&self, x: &Tensor) -> Result<Tensor> {
|
||||
let _enter = self.span.enter();
|
||||
let gate = self.gate_proj.forward(x)?.apply(&self.act_fn)?;
|
||||
let up = self.up_proj.forward(x)?;
|
||||
let gated = (gate * up)?;
|
||||
self.down_proj.forward(&gated)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct RotaryEmbedding {
|
||||
sin: Tensor,
|
||||
cos: Tensor,
|
||||
}
|
||||
|
||||
impl RotaryEmbedding {
|
||||
fn new(
|
||||
dtype: DType,
|
||||
head_dim: usize,
|
||||
max_position_embeddings: usize,
|
||||
rope_theta: f64,
|
||||
dev: &Device,
|
||||
) -> Result<Self> {
|
||||
let dim = head_dim;
|
||||
let max_seq_len = max_position_embeddings;
|
||||
let inv_freq: Vec<_> = (0..dim)
|
||||
.step_by(2)
|
||||
.map(|i| 1f32 / rope_theta.powf(i as f64 / dim as f64) as f32)
|
||||
.collect();
|
||||
let inv_freq_len = inv_freq.len();
|
||||
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
|
||||
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
|
||||
.to_dtype(dtype)?
|
||||
.reshape((max_seq_len, 1))?;
|
||||
let freqs = t.matmul(&inv_freq)?;
|
||||
Ok(Self {
|
||||
sin: freqs.sin()?,
|
||||
cos: freqs.cos()?,
|
||||
})
|
||||
}
|
||||
|
||||
/// Apply RoPE (q, k shape: B x H x L x D)
|
||||
fn apply(&self, q: &Tensor, k: &Tensor, offset: usize) -> Result<(Tensor, Tensor)> {
|
||||
let (_, _, seq_len, _) = q.dims4()?;
|
||||
let cos = self.cos.narrow(0, offset, seq_len)?.to_dtype(q.dtype())?;
|
||||
let sin = self.sin.narrow(0, offset, seq_len)?.to_dtype(q.dtype())?;
|
||||
let q_embed = candle_nn::rotary_emb::rope(&q.contiguous()?, &cos, &sin)?;
|
||||
let k_embed = candle_nn::rotary_emb::rope(&k.contiguous()?, &cos, &sin)?;
|
||||
Ok((q_embed, k_embed))
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct AttentionWeights {
|
||||
q_proj: QMatMul,
|
||||
k_proj: QMatMul,
|
||||
v_proj: QMatMul,
|
||||
o_proj: QMatMul,
|
||||
q_norm: RmsNorm,
|
||||
k_norm: RmsNorm,
|
||||
num_heads: usize,
|
||||
num_kv_heads: usize,
|
||||
num_kv_groups: usize,
|
||||
head_dim: usize,
|
||||
rotary_emb: Arc<RotaryEmbedding>,
|
||||
kv_cache: KvCache,
|
||||
span_attn: tracing::Span,
|
||||
}
|
||||
|
||||
impl AttentionWeights {
|
||||
fn new<R: Read + Seek>(
|
||||
gg: &mut Gguf<R>,
|
||||
num_heads: usize,
|
||||
num_kv_heads: usize,
|
||||
head_dim: usize,
|
||||
rms_norm_eps: f64,
|
||||
rotary_emb: Arc<RotaryEmbedding>,
|
||||
prefix: &str,
|
||||
) -> Result<Self> {
|
||||
let num_kv_groups = num_heads / num_kv_heads;
|
||||
|
||||
let q_proj = gg.qmatmul(&format!("{prefix}.attn_q.weight"))?;
|
||||
let k_proj = gg.qmatmul(&format!("{prefix}.attn_k.weight"))?;
|
||||
let v_proj = gg.qmatmul(&format!("{prefix}.attn_v.weight"))?;
|
||||
let o_proj = gg.qmatmul(&format!("{prefix}.attn_output.weight"))?;
|
||||
|
||||
let q_norm = gg.rms_norm(&format!("{prefix}.attn_q_norm.weight"), rms_norm_eps)?;
|
||||
let k_norm = gg.rms_norm(&format!("{prefix}.attn_k_norm.weight"), rms_norm_eps)?;
|
||||
|
||||
// Initialize KV cache with 512 tokens capacity to reduce initial memory allocation.
|
||||
// The cache will grow in chunks of 512 tokens when needed.
|
||||
let kv_cache = KvCache::new(2, 512);
|
||||
|
||||
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
|
||||
|
||||
Ok(Self {
|
||||
q_proj,
|
||||
k_proj,
|
||||
v_proj,
|
||||
o_proj,
|
||||
q_norm,
|
||||
k_norm,
|
||||
num_heads,
|
||||
num_kv_heads,
|
||||
num_kv_groups,
|
||||
head_dim,
|
||||
rotary_emb,
|
||||
kv_cache,
|
||||
span_attn,
|
||||
})
|
||||
}
|
||||
|
||||
fn forward(&mut self, x: &Tensor, attn_mask: Option<&Tensor>, offset: usize) -> Result<Tensor> {
|
||||
let _enter = self.span_attn.enter();
|
||||
let (b, l, _) = x.dims3()?;
|
||||
|
||||
let q = self.q_proj.forward(x)?;
|
||||
let k = self.k_proj.forward(x)?;
|
||||
let v = self.v_proj.forward(x)?;
|
||||
|
||||
let q = q
|
||||
.reshape((b, l, self.num_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let k = k
|
||||
.reshape((b, l, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let v = v
|
||||
.reshape((b, l, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
|
||||
let q_flat = q.flatten(0, 2)?;
|
||||
let k_flat = k.flatten(0, 2)?;
|
||||
|
||||
let q_flat = self.q_norm.forward(&q_flat)?;
|
||||
let k_flat = self.k_norm.forward(&k_flat)?;
|
||||
let q = q_flat.reshape((b, self.num_heads, l, self.head_dim))?;
|
||||
let k = k_flat.reshape((b, self.num_kv_heads, l, self.head_dim))?;
|
||||
|
||||
let (q, k) = self.rotary_emb.apply(&q, &k, offset)?;
|
||||
|
||||
// Reset KV cache if we're at the first position
|
||||
if offset == 0 {
|
||||
self.kv_cache.reset();
|
||||
}
|
||||
let (k, v) = self.kv_cache.append(&k.contiguous()?, &v.contiguous()?)?;
|
||||
|
||||
// Make tensor contiguous to avoid some strided copies
|
||||
let k = k.contiguous()?;
|
||||
let v = v.contiguous()?;
|
||||
|
||||
let k = repeat_kv(k, self.num_kv_groups)?.contiguous()?;
|
||||
let v = repeat_kv(v, self.num_kv_groups)?.contiguous()?;
|
||||
|
||||
let scale = 1.0 / (self.head_dim as f64).sqrt();
|
||||
let mut scores = (q.matmul(&k.transpose(2, 3)?)? * scale)?;
|
||||
if let Some(m) = attn_mask {
|
||||
let m_dtype = m.dtype();
|
||||
let scores_dtype = scores.dtype();
|
||||
let mask = if m_dtype != scores_dtype {
|
||||
m.to_dtype(scores_dtype)?
|
||||
} else {
|
||||
m.clone()
|
||||
};
|
||||
scores = scores.broadcast_add(&mask)?;
|
||||
}
|
||||
let probs = candle_nn::ops::softmax_last_dim(&scores)?;
|
||||
let ctx = probs.matmul(&v)?; // (B, H, L, D)
|
||||
let reshaped_ctx = ctx
|
||||
.transpose(1, 2)?
|
||||
.reshape((b, l, self.num_heads * self.head_dim))?;
|
||||
self.o_proj.forward(&reshaped_ctx)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct LayerWeights {
|
||||
self_attn: AttentionWeights,
|
||||
mlp: MlpWeights,
|
||||
ln1: RmsNorm,
|
||||
ln2: RmsNorm,
|
||||
}
|
||||
|
||||
impl LayerWeights {
|
||||
fn new<R: Read + Seek>(
|
||||
gg: &mut Gguf<R>,
|
||||
num_attention_heads: usize,
|
||||
num_key_value_heads: usize,
|
||||
head_dim: usize,
|
||||
rms_norm_eps: f64,
|
||||
rotary: Arc<RotaryEmbedding>,
|
||||
layer_idx: usize,
|
||||
) -> Result<Self> {
|
||||
let prefix = format!("blk.{layer_idx}");
|
||||
|
||||
let ln1 = gg.rms_norm(&format!("{prefix}.attn_norm.weight"), rms_norm_eps)?;
|
||||
let ln2 = gg.rms_norm(&format!("{prefix}.ffn_norm.weight"), rms_norm_eps)?;
|
||||
let self_attn = AttentionWeights::new(
|
||||
gg,
|
||||
num_attention_heads,
|
||||
num_key_value_heads,
|
||||
head_dim,
|
||||
rms_norm_eps,
|
||||
rotary,
|
||||
&prefix,
|
||||
)?;
|
||||
let mlp = MlpWeights::new(gg, &prefix)?;
|
||||
Ok(Self {
|
||||
self_attn,
|
||||
mlp,
|
||||
ln1,
|
||||
ln2,
|
||||
})
|
||||
}
|
||||
|
||||
fn forward(&mut self, x: &Tensor, mask: Option<&Tensor>, offset: usize) -> Result<Tensor> {
|
||||
let h = self.ln1.forward(x)?;
|
||||
let h = self.self_attn.forward(&h, mask, offset)?;
|
||||
let x = (x + h)?;
|
||||
let h2 = self.ln2.forward(&x)?;
|
||||
let h2 = h2.apply(&self.mlp)?;
|
||||
x + h2
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub struct ModelWeights {
|
||||
embed_tokens: Embedding,
|
||||
layers: Vec<LayerWeights>,
|
||||
norm: RmsNorm,
|
||||
lm_head: QMatMul,
|
||||
device: Device,
|
||||
dtype: DType,
|
||||
span: tracing::Span,
|
||||
span_output: tracing::Span,
|
||||
}
|
||||
|
||||
impl ModelWeights {
|
||||
pub fn from_gguf<R: Read + Seek>(
|
||||
ct: gguf_file::Content,
|
||||
reader: &mut R,
|
||||
device: &Device,
|
||||
) -> Result<Self> {
|
||||
let mut gg = Gguf::new(ct, reader, device.clone());
|
||||
let md_get = |s: &str| match gg.metadata().get(s) {
|
||||
None => candle::bail!("cannot find {s} in metadata"),
|
||||
Some(v) => Ok(v),
|
||||
};
|
||||
|
||||
let num_attention_heads = md_get("qwen3.attention.head_count")?.to_u32()? as usize;
|
||||
let num_kv_heads = md_get("qwen3.attention.head_count_kv")?.to_u32()? as usize;
|
||||
let head_dim = md_get("qwen3.attention.key_length")?.to_u32()? as usize;
|
||||
let num_layers = md_get("qwen3.block_count")?.to_u32()? as usize;
|
||||
let hidden_size = md_get("qwen3.embedding_length")?.to_u32()? as usize;
|
||||
let max_position_embeddings = md_get("qwen3.context_length")?.to_u32()? as usize;
|
||||
let rms_norm_eps = md_get("qwen3.attention.layer_norm_rms_epsilon")?.to_f32()? as f64;
|
||||
let rope_freq_base = md_get("qwen3.rope.freq_base")?.to_f32()? as f64;
|
||||
|
||||
let dtype = match gg.metadata().get("general.dtype") {
|
||||
Some(v) => match v.to_u32() {
|
||||
Ok(0) => DType::F32,
|
||||
Ok(1) => DType::F16,
|
||||
_ => DType::F16,
|
||||
},
|
||||
None => DType::F16,
|
||||
};
|
||||
|
||||
let embed_tensor = gg.tensor("token_embd.weight")?;
|
||||
let embed_tokens = Embedding::new(embed_tensor.dequantize(device)?, hidden_size);
|
||||
|
||||
let rotary = Arc::new(RotaryEmbedding::new(
|
||||
dtype,
|
||||
head_dim,
|
||||
max_position_embeddings,
|
||||
rope_freq_base,
|
||||
device,
|
||||
)?);
|
||||
|
||||
let mut layers = Vec::with_capacity(num_layers);
|
||||
for i in 0..num_layers {
|
||||
layers.push(LayerWeights::new(
|
||||
&mut gg,
|
||||
num_attention_heads,
|
||||
num_kv_heads,
|
||||
head_dim,
|
||||
rms_norm_eps,
|
||||
rotary.clone(),
|
||||
i,
|
||||
)?);
|
||||
}
|
||||
|
||||
let norm = gg.rms_norm("output_norm.weight", rms_norm_eps)?;
|
||||
// Load output projection tensor, falling back to tied embeddings like gemma3
|
||||
let lm_head_tensor = match gg.tensor("output.weight") {
|
||||
Ok(tensor) => tensor,
|
||||
Err(_) => gg.tensor("token_embd.weight")?,
|
||||
};
|
||||
let lm_head = QMatMul::from_weights(lm_head_tensor.into())?;
|
||||
let span = tracing::span!(tracing::Level::TRACE, "model");
|
||||
let span_output = tracing::span!(tracing::Level::TRACE, "output");
|
||||
Ok(Self {
|
||||
embed_tokens,
|
||||
layers,
|
||||
norm,
|
||||
lm_head,
|
||||
device: device.clone(),
|
||||
dtype,
|
||||
span,
|
||||
span_output,
|
||||
})
|
||||
}
|
||||
|
||||
fn causal_mask(
|
||||
&self,
|
||||
b: usize,
|
||||
tgt: usize,
|
||||
offset: usize,
|
||||
sw: Option<usize>,
|
||||
) -> Result<Tensor> {
|
||||
let minf = f32::NEG_INFINITY;
|
||||
let mask: Vec<_> = (0..tgt)
|
||||
.flat_map(|i| {
|
||||
(0..(tgt + offset)).map(move |j| {
|
||||
let past_ok = j <= i + offset;
|
||||
let sw_ok = match sw {
|
||||
Some(w) => (i + offset) as i64 - j as i64 <= w as i64,
|
||||
None => true,
|
||||
};
|
||||
if past_ok && sw_ok {
|
||||
0.
|
||||
} else {
|
||||
minf
|
||||
}
|
||||
})
|
||||
})
|
||||
.collect();
|
||||
Tensor::from_slice(&mask, (b, 1, tgt, tgt + offset), &self.device)?.to_dtype(self.dtype)
|
||||
}
|
||||
|
||||
pub fn forward(&mut self, input: &Tensor, offset: usize) -> Result<Tensor> {
|
||||
let _enter = self.span.enter();
|
||||
let (b, l) = input.dims2()?;
|
||||
let mut h = self.embed_tokens.forward(input)?;
|
||||
let causal_mask = if l == 1 {
|
||||
None
|
||||
} else {
|
||||
Some(self.causal_mask(b, l, offset, None)?)
|
||||
};
|
||||
for layer in &mut self.layers {
|
||||
h = layer.forward(&h, causal_mask.as_ref(), offset)?;
|
||||
}
|
||||
let h = self.norm.forward(&h)?;
|
||||
let _enter = self.span_output.enter();
|
||||
let last_hidden = h.narrow(1, l - 1, 1)?;
|
||||
self.lm_head.forward(&last_hidden)?.squeeze(1)
|
||||
}
|
||||
}
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - [Gemma Paper](https://arxiv.org/abs/2401.06751)
|
||||
//! - [Gemma Paper](https://huggingface.co/papers/2401.06751)
|
||||
//! - [Model Card](https://ai.google.dev/gemma)
|
||||
//!
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
//! - Support for 8-bit quantization
|
||||
//!
|
||||
//! References:
|
||||
//! - 📝 [T5 Paper](https://arxiv.org/abs/1910.10683)
|
||||
//! - 📝 [T5 Paper](https://huggingface.co/papers/1910.10683)
|
||||
//! - 🤗 [Model Card](https://huggingface.co/t5-base)
|
||||
//! - 🤗 Original model from [T5](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py)
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
//! - Rotary positional embeddings (RoPE)
|
||||
//!
|
||||
//! References:
|
||||
//! - [Qwen2 Paper](https://arxiv.org/abs/2401.08985)
|
||||
//! - [Qwen2 Paper](https://huggingface.co/papers/2401.08985)
|
||||
//! - [Model Card](https://huggingface.co/Qwen/Qwen2-7B-beta)
|
||||
//!
|
||||
|
||||
|
||||
387
candle-transformers/src/models/qwen3.rs
Normal file
387
candle-transformers/src/models/qwen3.rs
Normal file
@ -0,0 +1,387 @@
|
||||
use crate::{
|
||||
models::with_tracing::{linear_b, linear_no_bias, Linear, RmsNorm},
|
||||
utils::repeat_kv,
|
||||
};
|
||||
use candle::{DType, Device, Module, Result, Tensor};
|
||||
use candle_nn::{kv_cache::KvCache, Activation, VarBuilder};
|
||||
use std::sync::Arc;
|
||||
|
||||
#[derive(Debug, Clone, PartialEq, serde::Deserialize)]
|
||||
pub struct Config {
|
||||
pub vocab_size: usize,
|
||||
pub hidden_size: usize,
|
||||
pub intermediate_size: usize,
|
||||
pub num_hidden_layers: usize,
|
||||
pub num_attention_heads: usize,
|
||||
pub head_dim: usize,
|
||||
pub attention_bias: bool,
|
||||
pub num_key_value_heads: usize,
|
||||
pub max_position_embeddings: usize,
|
||||
pub sliding_window: Option<usize>,
|
||||
pub max_window_layers: usize,
|
||||
pub tie_word_embeddings: bool,
|
||||
pub rope_theta: f64,
|
||||
pub rms_norm_eps: f64,
|
||||
pub use_sliding_window: bool,
|
||||
pub hidden_act: Activation,
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub(crate) struct Qwen3RotaryEmbedding {
|
||||
sin: Tensor,
|
||||
cos: Tensor,
|
||||
}
|
||||
|
||||
impl Qwen3RotaryEmbedding {
|
||||
pub(crate) fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
|
||||
let dim = cfg.head_dim;
|
||||
let max_seq_len = cfg.max_position_embeddings;
|
||||
let inv_freq: Vec<_> = (0..dim)
|
||||
.step_by(2)
|
||||
.map(|i| 1f32 / cfg.rope_theta.powf(i as f64 / dim as f64) as f32)
|
||||
.collect();
|
||||
let inv_freq_len = inv_freq.len();
|
||||
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
|
||||
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
|
||||
.to_dtype(dtype)?
|
||||
.reshape((max_seq_len, 1))?;
|
||||
let freqs = t.matmul(&inv_freq)?;
|
||||
Ok(Self {
|
||||
sin: freqs.sin()?,
|
||||
cos: freqs.cos()?,
|
||||
})
|
||||
}
|
||||
|
||||
/// Apply RoPE (q, k shape: B x H x L x D)
|
||||
pub(crate) fn apply(&self, q: &Tensor, k: &Tensor, offset: usize) -> Result<(Tensor, Tensor)> {
|
||||
let (_, _, seq_len, _) = q.dims4()?;
|
||||
let cos = self.cos.narrow(0, offset, seq_len)?;
|
||||
let sin = self.sin.narrow(0, offset, seq_len)?;
|
||||
let q_embed = candle_nn::rotary_emb::rope(&q.contiguous()?, &cos, &sin)?;
|
||||
let k_embed = candle_nn::rotary_emb::rope(&k.contiguous()?, &cos, &sin)?;
|
||||
Ok((q_embed, k_embed))
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub(crate) struct Qwen3MLP {
|
||||
gate_proj: Linear,
|
||||
up_proj: Linear,
|
||||
down_proj: Linear,
|
||||
act_fn: Activation,
|
||||
}
|
||||
|
||||
impl Qwen3MLP {
|
||||
pub(crate) fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
Ok(Self {
|
||||
gate_proj: linear_no_bias(cfg.hidden_size, cfg.intermediate_size, vb.pp("gate_proj"))?,
|
||||
up_proj: linear_no_bias(cfg.hidden_size, cfg.intermediate_size, vb.pp("up_proj"))?,
|
||||
down_proj: linear_no_bias(cfg.intermediate_size, cfg.hidden_size, vb.pp("down_proj"))?,
|
||||
act_fn: cfg.hidden_act,
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
impl Module for Qwen3MLP {
|
||||
fn forward(&self, x: &Tensor) -> Result<Tensor> {
|
||||
let lhs = x.apply(&self.gate_proj)?.apply(&self.act_fn)?;
|
||||
let rhs = x.apply(&self.up_proj)?;
|
||||
(lhs * rhs)?.apply(&self.down_proj)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub(crate) struct Qwen3Attention {
|
||||
// projections
|
||||
q_proj: Linear,
|
||||
k_proj: Linear,
|
||||
v_proj: Linear,
|
||||
o_proj: Linear,
|
||||
// norms
|
||||
q_norm: RmsNorm,
|
||||
k_norm: RmsNorm,
|
||||
// hyper params
|
||||
num_heads: usize,
|
||||
num_kv_heads: usize,
|
||||
num_kv_groups: usize,
|
||||
head_dim: usize,
|
||||
hidden_size: usize,
|
||||
// utils
|
||||
rotary_emb: Arc<Qwen3RotaryEmbedding>,
|
||||
kv_cache: KvCache,
|
||||
}
|
||||
|
||||
impl Qwen3Attention {
|
||||
pub(crate) fn new(
|
||||
cfg: &Config,
|
||||
rotary_emb: Arc<Qwen3RotaryEmbedding>,
|
||||
vb: VarBuilder,
|
||||
) -> Result<Self> {
|
||||
if cfg.use_sliding_window {
|
||||
candle::bail!("sliding window is not suppored")
|
||||
}
|
||||
|
||||
let head_dim = cfg.head_dim;
|
||||
let num_heads = cfg.num_attention_heads;
|
||||
let num_kv_heads = cfg.num_key_value_heads;
|
||||
let num_kv_groups = num_heads / num_kv_heads;
|
||||
|
||||
let q_proj = linear_b(
|
||||
cfg.hidden_size,
|
||||
num_heads * head_dim,
|
||||
cfg.attention_bias,
|
||||
vb.pp("q_proj"),
|
||||
)?;
|
||||
let k_proj = linear_b(
|
||||
cfg.hidden_size,
|
||||
num_kv_heads * head_dim,
|
||||
cfg.attention_bias,
|
||||
vb.pp("k_proj"),
|
||||
)?;
|
||||
let v_proj = linear_b(
|
||||
cfg.hidden_size,
|
||||
num_kv_heads * head_dim,
|
||||
cfg.attention_bias,
|
||||
vb.pp("v_proj"),
|
||||
)?;
|
||||
let o_proj = linear_b(
|
||||
num_heads * head_dim,
|
||||
cfg.hidden_size,
|
||||
cfg.attention_bias,
|
||||
vb.pp("o_proj"),
|
||||
)?;
|
||||
|
||||
let q_norm = RmsNorm::new(head_dim, cfg.rms_norm_eps, vb.pp("q_norm"))?;
|
||||
let k_norm = RmsNorm::new(head_dim, cfg.rms_norm_eps, vb.pp("k_norm"))?;
|
||||
|
||||
// Necessary because the hidden_size in the config isn't always accurate
|
||||
let hidden_size = head_dim * cfg.num_attention_heads;
|
||||
|
||||
let kv_cache = KvCache::new(2, cfg.max_position_embeddings);
|
||||
|
||||
Ok(Self {
|
||||
q_proj,
|
||||
k_proj,
|
||||
v_proj,
|
||||
o_proj,
|
||||
q_norm,
|
||||
k_norm,
|
||||
num_heads,
|
||||
num_kv_heads,
|
||||
num_kv_groups,
|
||||
head_dim,
|
||||
hidden_size,
|
||||
rotary_emb,
|
||||
kv_cache,
|
||||
})
|
||||
}
|
||||
|
||||
pub(crate) fn forward(
|
||||
&mut self,
|
||||
x: &Tensor,
|
||||
attn_mask: Option<&Tensor>,
|
||||
offset: usize,
|
||||
) -> Result<Tensor> {
|
||||
let (b, l, _) = x.dims3()?;
|
||||
|
||||
// 1. Proj
|
||||
let q = self.q_proj.forward(x)?;
|
||||
let k = self.k_proj.forward(x)?;
|
||||
let v = self.v_proj.forward(x)?;
|
||||
|
||||
// 2. Reshape: (B, L, H, D) -> (B, H, L, D)
|
||||
let q = q
|
||||
.reshape((b, l, self.num_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let k = k
|
||||
.reshape((b, l, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
let v = v
|
||||
.reshape((b, l, self.num_kv_heads, self.head_dim))?
|
||||
.transpose(1, 2)?;
|
||||
|
||||
// 3. Per‑head RMSNorm
|
||||
let q_flat = q.flatten(0, 2)?; // (B*H, L, D) -> (BHL, D) after transpose later
|
||||
let k_flat = k.flatten(0, 2)?;
|
||||
let q_flat = self.q_norm.forward(&q_flat)?;
|
||||
let k_flat = self.k_norm.forward(&k_flat)?;
|
||||
let q = q_flat.reshape((b, self.num_heads, l, self.head_dim))?;
|
||||
let k = k_flat.reshape((b, self.num_kv_heads, l, self.head_dim))?;
|
||||
|
||||
// 4. RoPE
|
||||
let (q, k) = self.rotary_emb.apply(&q, &k, offset)?;
|
||||
|
||||
// 5. Accumulate KV cache
|
||||
let (k, v) = self.kv_cache.append(&k.contiguous()?, &v.contiguous()?)?;
|
||||
|
||||
// 6. GQA repeat_kv
|
||||
let k = repeat_kv(k, self.num_kv_groups)?;
|
||||
let v = repeat_kv(v, self.num_kv_groups)?;
|
||||
|
||||
// 7. Attention score
|
||||
let scale = 1.0 / (self.head_dim as f64).sqrt();
|
||||
let mut scores = (q.matmul(&k.transpose(2, 3)?)? * scale)?;
|
||||
if let Some(m) = attn_mask {
|
||||
scores = scores.broadcast_add(m)?;
|
||||
}
|
||||
let probs = candle_nn::ops::softmax_last_dim(&scores)?;
|
||||
let ctx = probs.matmul(&v)?; // (B, H, L, D)
|
||||
|
||||
// 8. Output proj
|
||||
ctx.transpose(1, 2)?
|
||||
.reshape((b, l, self.hidden_size))?
|
||||
.apply(&self.o_proj)
|
||||
}
|
||||
|
||||
pub(crate) fn clear_kv_cache(&mut self) {
|
||||
self.kv_cache.reset();
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
struct DecoderLayer {
|
||||
self_attn: Qwen3Attention,
|
||||
mlp: Qwen3MLP,
|
||||
ln1: RmsNorm,
|
||||
ln2: RmsNorm,
|
||||
}
|
||||
|
||||
impl DecoderLayer {
|
||||
fn new(cfg: &Config, rotary: Arc<Qwen3RotaryEmbedding>, vb: VarBuilder) -> Result<Self> {
|
||||
let self_attn = Qwen3Attention::new(cfg, rotary, vb.pp("self_attn"))?;
|
||||
let mlp = Qwen3MLP::new(cfg, vb.pp("mlp"))?;
|
||||
let ln1 = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("input_layernorm"))?;
|
||||
let ln2 = RmsNorm::new(
|
||||
cfg.hidden_size,
|
||||
cfg.rms_norm_eps,
|
||||
vb.pp("post_attention_layernorm"),
|
||||
)?;
|
||||
Ok(Self {
|
||||
self_attn,
|
||||
mlp,
|
||||
ln1,
|
||||
ln2,
|
||||
})
|
||||
}
|
||||
|
||||
fn forward(&mut self, x: &Tensor, mask: Option<&Tensor>, offset: usize) -> Result<Tensor> {
|
||||
let h = self.ln1.forward(x)?;
|
||||
let h = self.self_attn.forward(&h, mask, offset)?;
|
||||
let x = (x + h)?;
|
||||
let h2 = self.ln2.forward(&x)?;
|
||||
let h2 = h2.apply(&self.mlp)?;
|
||||
x + h2
|
||||
}
|
||||
|
||||
fn clear_kv_cache(&mut self) {
|
||||
self.self_attn.clear_kv_cache();
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub struct Model {
|
||||
embed_tokens: candle_nn::Embedding,
|
||||
layers: Vec<DecoderLayer>,
|
||||
norm: RmsNorm,
|
||||
device: Device,
|
||||
dtype: DType,
|
||||
}
|
||||
|
||||
impl Model {
|
||||
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let embed_tokens =
|
||||
candle_nn::embedding(cfg.vocab_size, cfg.hidden_size, vb.pp("model.embed_tokens"))?;
|
||||
let rotary = Arc::new(Qwen3RotaryEmbedding::new(vb.dtype(), cfg, vb.device())?);
|
||||
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
|
||||
let vb_l = vb.pp("model.layers");
|
||||
for i in 0..cfg.num_hidden_layers {
|
||||
layers.push(DecoderLayer::new(cfg, rotary.clone(), vb_l.pp(i))?);
|
||||
}
|
||||
Ok(Self {
|
||||
embed_tokens,
|
||||
layers,
|
||||
norm: RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("model.norm"))?,
|
||||
device: vb.device().clone(),
|
||||
dtype: vb.dtype(),
|
||||
})
|
||||
}
|
||||
|
||||
fn clear_kv_cache(&mut self) {
|
||||
for l in &mut self.layers {
|
||||
l.clear_kv_cache();
|
||||
}
|
||||
}
|
||||
|
||||
fn causal_mask(
|
||||
&self,
|
||||
b: usize,
|
||||
tgt: usize,
|
||||
offset: usize,
|
||||
sw: Option<usize>,
|
||||
) -> Result<Tensor> {
|
||||
let minf = f32::NEG_INFINITY;
|
||||
let mask: Vec<_> = (0..tgt)
|
||||
.flat_map(|i| {
|
||||
(0..(tgt + offset)).map(move |j| {
|
||||
let past_ok = j <= i + offset;
|
||||
let sw_ok = match sw {
|
||||
Some(w) => (i + offset) as i64 - j as i64 <= w as i64,
|
||||
None => true,
|
||||
};
|
||||
if past_ok && sw_ok {
|
||||
0.
|
||||
} else {
|
||||
minf
|
||||
}
|
||||
})
|
||||
})
|
||||
.collect();
|
||||
Tensor::from_slice(&mask, (b, 1, tgt, tgt + offset), &self.device)?.to_dtype(self.dtype)
|
||||
}
|
||||
|
||||
pub fn forward(&mut self, input: &Tensor, offset: usize) -> Result<Tensor> {
|
||||
let (b, l) = input.dims2()?;
|
||||
let mut h = self.embed_tokens.forward(input)?;
|
||||
|
||||
let causal = if l == 1 {
|
||||
None
|
||||
} else {
|
||||
Some(self.causal_mask(b, l, offset, None)?)
|
||||
};
|
||||
|
||||
for layer in &mut self.layers {
|
||||
h = layer.forward(&h, causal.as_ref(), offset)?;
|
||||
}
|
||||
self.norm.forward(&h)
|
||||
}
|
||||
}
|
||||
|
||||
#[derive(Debug, Clone)]
|
||||
pub struct ModelForCausalLM {
|
||||
base: Model,
|
||||
lm_head: Linear,
|
||||
}
|
||||
|
||||
impl ModelForCausalLM {
|
||||
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
|
||||
let base = Model::new(cfg, vb.clone())?;
|
||||
let lm_head = if cfg.tie_word_embeddings {
|
||||
Linear::from_weights(base.embed_tokens.embeddings().clone(), None)
|
||||
} else {
|
||||
linear_no_bias(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?
|
||||
};
|
||||
Ok(Self { base, lm_head })
|
||||
}
|
||||
|
||||
pub fn forward(&mut self, input: &Tensor, offset: usize) -> Result<Tensor> {
|
||||
let (_, l) = input.dims2()?;
|
||||
self.base
|
||||
.forward(input, offset)?
|
||||
.narrow(1, l - 1, 1)?
|
||||
.apply(&self.lm_head)
|
||||
}
|
||||
|
||||
pub fn clear_kv_cache(&mut self) {
|
||||
self.base.clear_kv_cache();
|
||||
}
|
||||
}
|
||||
@ -12,7 +12,7 @@
|
||||
//!
|
||||
//! References:
|
||||
//! - [Gemma: Open Models Based on Gemini Technology](https://blog.google/technology/developers/gemma-open-models/)
|
||||
//! - [Recurrent Memory model architecture](https://arxiv.org/abs/2402.00441)
|
||||
//! - [Recurrent Memory model architecture](https://huggingface.co/papers/2402.00441)
|
||||
//!
|
||||
//! This implementation is based on the python version from huggingface/transformers.
|
||||
//! https://github.com/huggingface/transformers/blob/b109257f4fb8b1166e7c53cc5418632014ed53a5/src/transformers/models/recurrent_gemma/modeling_recurrent_gemma.py#L2
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
//! - High accuracy with VGG-like plain architecture and training
|
||||
//!
|
||||
//! References:
|
||||
//! - [RepVGG Paper](https://arxiv.org/abs/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
|
||||
//! - [RepVGG Paper](https://huggingface.co/papers/2101.03697). RepVGG: Making VGG-style ConvNets Great Again
|
||||
//! - [Official Implementation](https://github.com/DingXiaoH/RepVGG)
|
||||
//!
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@
|
||||
//!
|
||||
//! ## Reference
|
||||
//!
|
||||
//! [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
|
||||
//! [Deep Residual Learning for Image Recognition](https://huggingface.co/papers/1512.03385)
|
||||
//! He et al. (2015)
|
||||
//!
|
||||
//! This paper introduced ResNet, a deep neural network architecture that utilizes
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
//! - Lightweight all-MLP decode head
|
||||
//!
|
||||
//! References:
|
||||
//! - [SegFormer Paper](https://arxiv.org/abs/2105.15203)
|
||||
//! - [SegFormer Paper](https://huggingface.co/papers/2105.15203)
|
||||
//! - [Model Card](https://huggingface.co/nvidia/mit-b0)
|
||||
//!
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user